本系列文章配套代码获取有以下两种途径:
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1XuxKa9_G00NznvSK0cr5qw?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/PyTorchPython中列表list是一种动态数组,它能够容纳任意类型的对象,并且可以随着需要而增长或缩小。在内存分配方面,Python列表并不是直接存储数据,而是存储了对数据的引用。这意味着列表中的每个元素实际上是一个指向内存中某处的指针,该处存储了实际的数据。
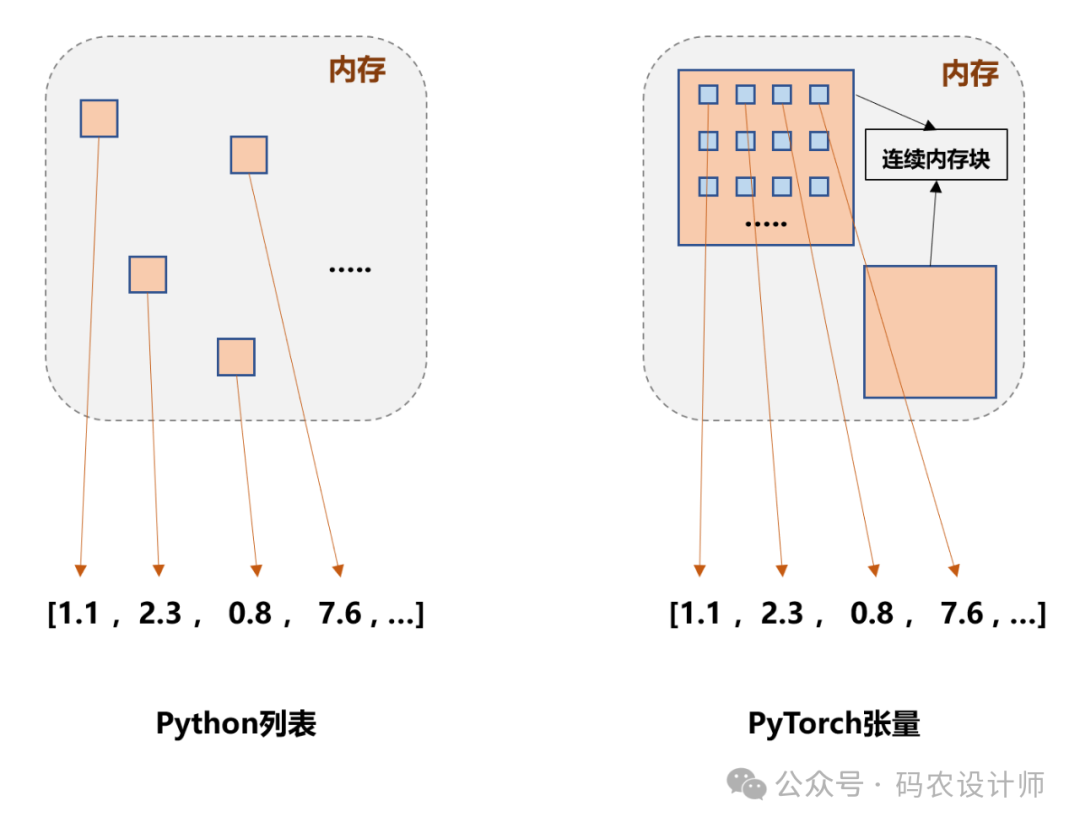
张量的存储视图:
>>> a = torch.arange(6).reshape(2,3)
>>> a
tensor([[0, 1, 2],
[3, 4, 5]])
# 对张量a进行reshape操作
>>> b = a.reshape(3,2)
>>> b
tensor([[0, 1],
[2, 3],
[4, 5]])
# 对张量a进行索引切片操作
>>> c = a[:,:2]
>>> c
tensor([[0, 1],
[3, 4]])
# 判断三个tensor的存储区的内存地址是否一样
>>> a.untyped_storage().data_ptr() == b.untyped_storage().data_ptr() == c.untyped_storage().data_ptr()
True
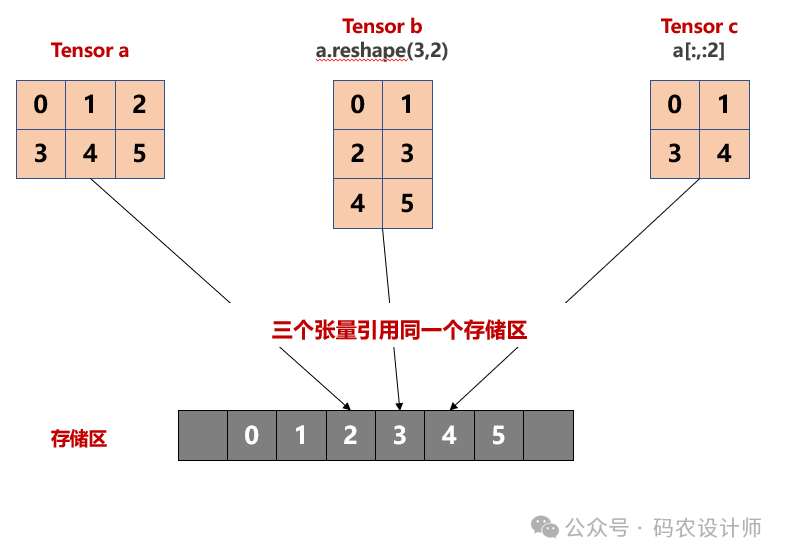
>>> c[0,0] = 9
>>> a
tensor([[9, 1, 2],
[3, 4, 5]])
>>> b
tensor([[9, 1],
[2, 3],
[4, 5]])
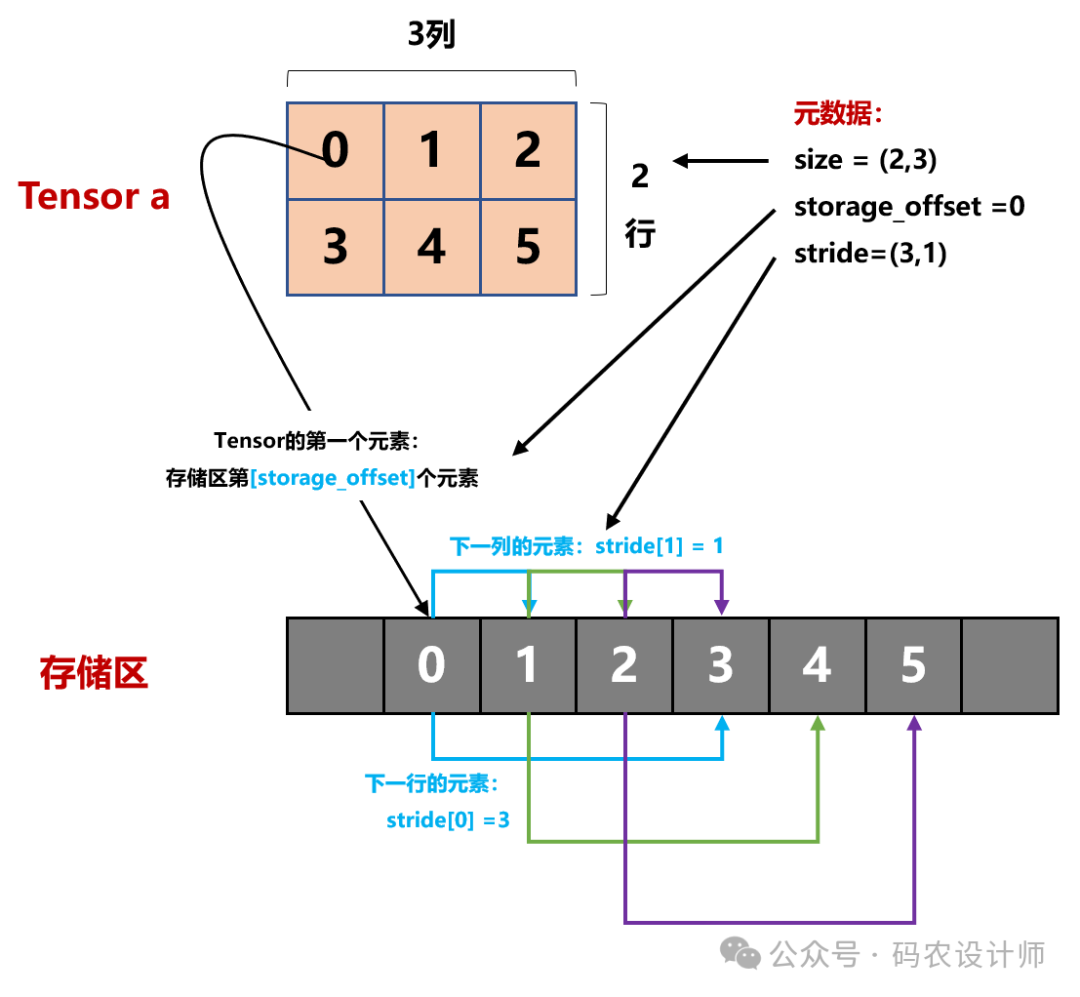
张量元数据:
-
形状是一个元祖,用于表示张量在每个维度上有多少个元素,通过tensor.size()获取; -
偏移量是指在tensor的第一个元素与storage的第一个元素的偏移量,通过tensor.storage_offset()获取; -
步长是一个元祖,指在存储区中为了获得下一个元素需要跳过的元素数量,通过tensor.stride()获取。
# 张量a、b、c的形状
>>> a.size() , b.size() , c.size()
(torch.Size([2, 3]), torch.Size([3, 2]), torch.Size([2, 2]))
# 张量a、b、c的步长
>>> a.stride() , b.stride() , c.stride()
((3, 1), (2, 1), (3, 1))
# 张量a、b、c的偏移量
>>> a.storage_offset() , b.storage_offset() , b.storage_offset()
(0, 0, 0)
-
张量a中的第一个元素0,与storage的第一个元素的偏移量storage_offset=0,即存储区第1个元素; -
步长stride=(3,1),即在行方向上为了获得下一个元素需要跳过1个元素,在列方向上为了获得下一个元素需要跳过3个元素。
更多内容可以前往官网查看:
https://pytorch.org/


本篇文章来源于微信公众号: 码农设计师
{kind=link}