本系列文章配套代码获取有以下两种途径:
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1XuxKa9_G00NznvSK0cr5qw?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/PyTorch池化层:
-
最大池化(Max Pooling):
在给定的池化窗口内选择最大的值作为输出。该方法能够消除输入中不相关的信息,提取出最具有代表性的特征。最大池化在深度卷积神经网络中被广泛应用,可以在一定程度上减轻过拟合的问题。
-
平均池化(Average Pooling):
-
随机池化(Stochastic Pooling):
-
全局池化(Global Pooling):
-
重叠池化(Overlapping Pooling):
-
空金字塔池化(Spatial Pyramid Pooling, SPP):
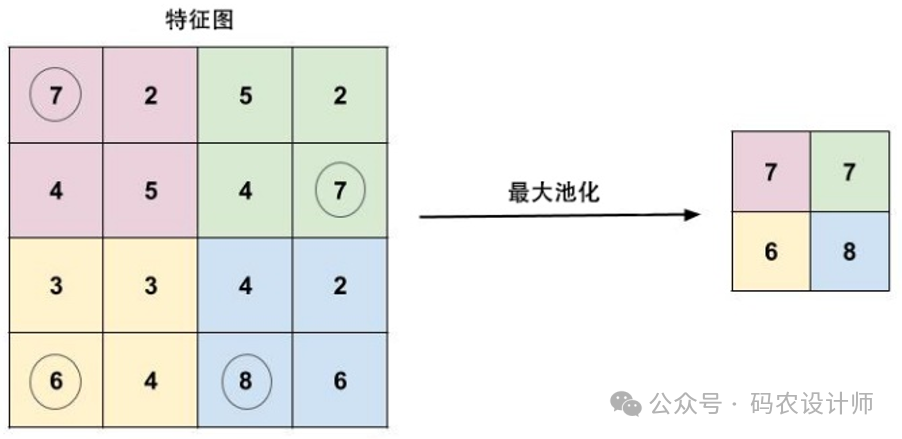
构造函数:
在PyTorch中,池化层的构造函数通常用于创建不同类型的池化层实例。以下是最大池化和平均池化的构造函数及其参数说明:
-
nn.MaxPool2d:
nn.MaxPool2d(kernel_size,
stride=None,
padding=0,
dilation=1,
return_indices=False,
ceil_mode=False)
其中:
-
kernel_size: 池化窗口的大小,可以是一个单一数字或者一个二元组 (height, width)。 -
stride: 池化操作的步长,可以是一个数字或者一个二元组 (stride_height, stride_width)。默认值是 kernel_size。 -
padding: 在输入数据的边缘添加的隐式零填充,可以是一个数字或者一个二元组 (pad_height, pad_width)。默认值是0。 -
dilation: 控制池化窗口中元素的间距,可以是一个数字或者一个二元组 (dilation_height, dilation_width)。默认值是1。 -
return_indices: 如果设置为 True,将返回每个最大值的索引,这有时在Unpooling操作中是有用的。默认值是 False。 -
ceil_mode: 如果设置为 True,将使用ceil而不是floor来计算输出形状。默认值是 False。
-
nn.AvgPool2d:
nn.AvgPool2d(kernel_size,
stride=None,
padding=0,
ceil_mode=False,
count_include_pad=True,
divisor_override=None)
参数与 nn.MaxPool2d 类似,但有两个额外的参数:
-
count_include_pad: 如果设置为 True,在计算平均值时会将填充的零值也考虑在内。默认值是 True。 -
divisor_override: 如果指定,它将用作除数,否则将使用池化区域的大小作为除数。默认值是 None。
池化操作:
本次仍以经典的Lena图作为处理图像。
lena = Image.open('lena.png')
# 将其转换为PyTorch张量
to_tensor = transforms.ToTensor()
lena_tensor = to_tensor(lena).unsqueeze(0)
在这个例子中,创建了两个池化层:一个是平均池化层,另一个是最大池化层。两者的池化窗口大小都是2×2。原始图像是200×200,池化窗口大小为2×2,因此池化后的图像尺寸将是原始图像尺寸的一半,所以最终的输出形状是(1, 1, 100, 100)。最前面的1表示批处理大小(batch size)。
# 平均池化(Average Pooling),池化窗口大小为2x2
pool_avg = nn.AvgPool2d(2,2)
# 最大池化(Max Pooling),池化窗口大小为2x2
pool_max = nn.MaxPool2d(2,2)
# 可以看到池化层没有学习参数
list(pool_avg.parameters()) , list(pool_max.parameters())
# 对图像张量进行池化操作
out_avg = pool_avg(lena_tensor)
out_max = pool_max(lena_tensor)
# 查看输出特征图大小
out_avg.shape , out_max.shape
# 输出结果:(torch.Size([1, 1, 100, 100]), torch.Size([1, 1, 100, 100]))
通过matplotlib对输出的三个特征图及原图进行可视化(为了保持图像的相对尺寸大小,采用subplot2grid的方式创建子图布局):
# 创建2行3列的子图布局
plt.figure(figsize=(12,8))
# 位置从(0, 0)开始,占用2行,2列
ax1 = plt.subplot2grid((2,3) , (0,0) , rowspan=2, colspan=2)
# 位置从(0, 2)开始,占用1行,1列
ax2 = plt.subplot2grid((2,3) , (0,2))
# 位置从(1, 2)开始,占用1行,1列
ax3 = plt.subplot2grid((2,3) , (1,2))
# 原图
ax1.imshow(lena,cmap='gray')
ax1.set_title('lena')
ax1.axis('off')
# 平均池化(Average Pooling)
ax2.imshow(out_avg,cmap='gray')
ax2.set_title('Average Pooling')
ax2.axis('off')
# 最大池化(Max Pooling)
ax3.imshow(out_max,cmap='gray')
ax3.set_title('Max Pooling')
ax3.axis('off')
plt.show()
可视化结果如下图所示:

更多内容可以前往官网查看:
https://pytorch.org/


本篇文章来源于微信公众号: 码农设计师
{kind=link}