本系列配套练习数据下载链接:
链接:https://pan.baidu.com/s/1imKDcw9wZWk_ItR8fwugZw?pwd=mnsj提取码:mnsj
分析模式工具集能够提供对宏观空间模式进行量化的统计数据。这意味着,通过这些工具,可以将地理空间中的模式或趋势(例如,空间聚类的存在与否以及聚类程度的动态变化等)转换为具体的数值或指标,从而更客观地理解和分析这些数据。
分析模式工具集包含平均最近邻、高/低聚类、增量空间自相关、多距离空间聚类分析(Ripley’s K 函数)、空间自相关(Morans I)五个工具。
本次主要介绍高/低聚类(Getis-Ord General G)工具。
-
1、概念:
高/低聚类(Getis-Ord General G)工具用于统计可度量高值或低值的聚类程度。该工具能够针对输入的要素类数据,计算并评估属性值在空间上的聚类模式,从而帮助用户识别出具有显著性的高值聚集区域或低值聚集区域。
对于线和面要素,距离计算中会使用要素的质心。对于多点、折线或由多部分组成的面,将会使用所有要素部分的加权平均中心来计算质心。点要素的加权项是 1,线要素的加权项是长度,而面要素的加权项是面积。
—————-
-
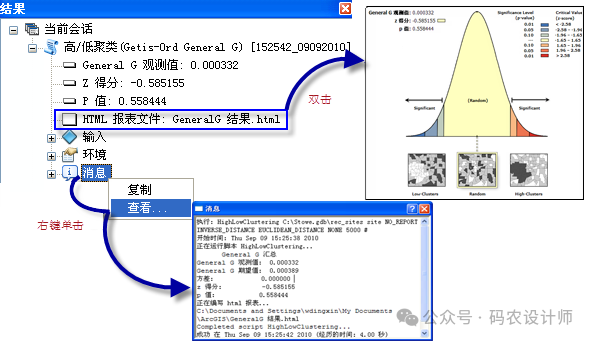
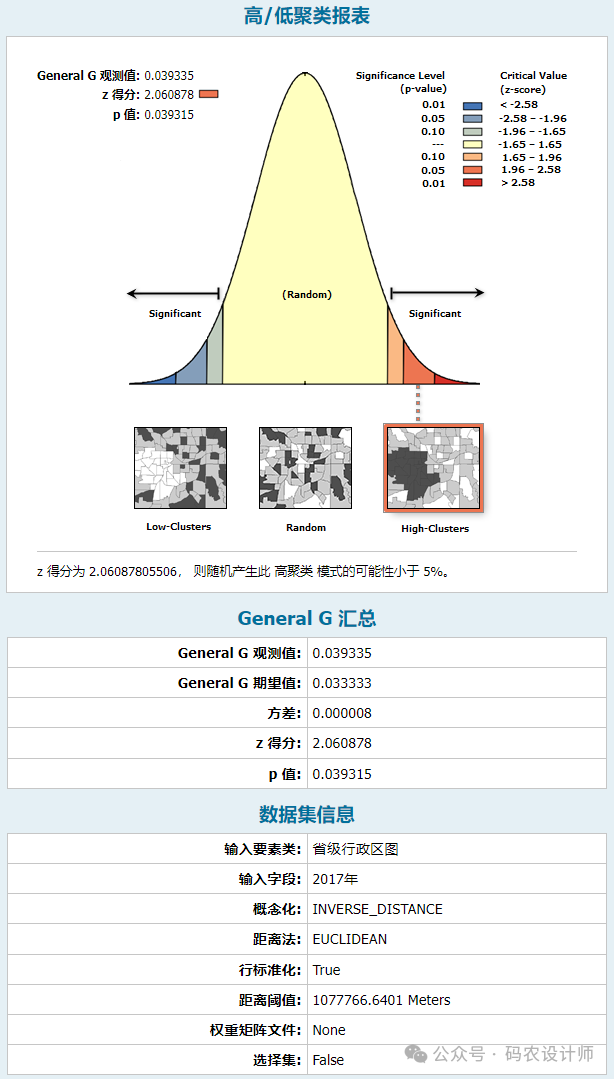
General G 观测值:根据输入数据实际计算出的Getis-Ord General G统计量的值。它反映了在研究区域内,高值或低值的实际聚集程度。如果观测值较高,可能意味着存在显著的高值聚集;如果观测值较低,则可能表明存在低值聚集。
-
General G 期望值:在假设数据随机分布的情况下,Getis-Ord General G统计量的期望值。换句话说,如果数据真的是随机分布的,没有空间聚类,那么我们应该期望得到的General G值就是这个期望值。它是用来与观测值进行比较的基准。
-
z 得分:观测值与期望值之间的标准化差异。它表示观测到的空间聚类程度与随机分布下期望的聚类程度之间的差异有多少个标准差。z 得分越高(或越低),聚类程度就越高。如果 z 得分接近零,则表示研究区域内不存在明显的聚类。z 得分为正表示高值的聚类。z 得分为负表示低值的聚类。
-
p 值:统计显著性的一个度量,用于检验零假设(即数据随机分布,不存在空间聚类)是否可以被拒绝。具体来说,p 值表示在零假设为真的情况下,观察到当前或更极端结果的概率。如果 p 值很小(通常小于预设的显著性水平,如0.05),则意味着观察到的数据分布与随机分布的差异不太可能是由偶然因素造成的,因此我们有理由拒绝零假设,认为数据存在显著的空间聚类。
图片来源:ArcMap官方文档
—————-
需要注意的是,高/低聚类(Getis-Ord General G)工具只处理正值数据,因此对于包含负值的数据集,需要进行适当的预处理或转换。此外,该工具还要求输入的要素类数据应包含一定程度的变化,如果所有数据都相同,则无法进行有效的分析(例如,如果所有输入都是1便无法求解)。
-
INVERSE_DISTANCE:反距离。这种概念化方法认为,距离越近的要素对目标要素的影响越大。具体来说,要素之间的权重会根据它们之间的距离的倒数来计算。这意味着非常靠近的要素将具有较大的权重,而距离较远的要素则具有较小的权重;
-
INVERSE_DISTANCE_SQUARED:反距离平方。与反距离类似,但权重的衰减速度更快。权重是根据要素之间距离的倒数的平方来计算的。这种方法进一步强调了近距离要素的重要性,并更快地减小了远距离要素的影响;
-
FIXED_DISTANCE_BAND:固定距离范围。在此概念化下,用户定义一个固定的距离阈值。在这个距离内的所有要素都被视为对目标要素有相同的影响(将分配值为 1 的权重),而超过这个距离的要素则被视为无影响(将分配值为 0 的权重)。
-
ZONE_OF_INDIFFERENCE:无差别区域。这种方法结合了固定距离和反距离的概念。在指定的临界距离(或区域)内,所有要素对目标要素的影响被视为相同(无差别),而一旦超过这个区域,要素的影响将开始按照距离衰减(例如,使用反距离方法)。
-
CONTIGUITY_EDGES_ONLY:仅边相邻。这种概念化适用于面状要素,只有共用边界或重叠的相邻面要素会影响目标面要素的计算,不考虑仅通过角点相连的要素。
-
CONTIGUITY_EDGES_CORNERS:边和角相邻。这也是针对面状要素的概念化方法。在这种方法下,共享边界、节点或重叠的面要素会影响目标面要素的计算。这比“仅边相邻”更为宽松,因为它允许通过角点相连的要素也被视为相邻。
-
GET_SPATIAL_WEIGHTS_FROM_FILE:从文件获取空间权重。该选项允许用户从外部文件加载预定义的空间权重矩阵,而不是使用上述任何内置的概念化方法来计算权重。这为用户提供了更大的灵活性,可以根据特定的分析需求自定义空间关系。指向空间权重文件的路径由 Weights_Matrix_File 参数指定。
这些概念化参数在空间分析中起着至关重要的作用,因为它们决定了如何量化要素之间的空间关系,从而影响最终的聚类或空间自相关分析结果。关于空间关系的概念化的选择建议,可以查看官方文档:
https://desktop.arcgis.com/zh-cn/arcmap/latest/tools/spatial-statistics-toolbox/modeling-spatial-relationships.htm#GUID-729B3B01-6911-41E9-AA99-8A4CF74EEE27
-
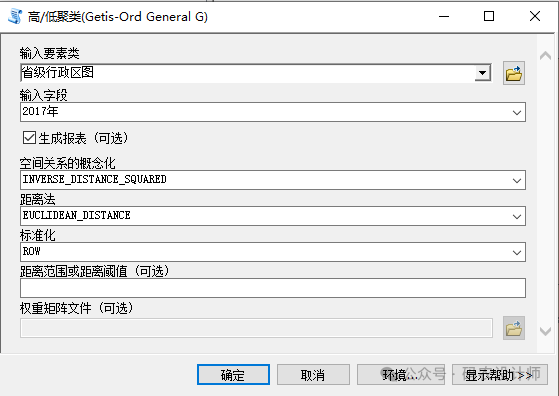
2、工具:
-
输入字段:要评估的数值字段(非负值)。如果输入字段包含负值,将显示错误消息; -
生成报表:勾选该选项,以便能得到详细的分析结果报告; -
空间关系的概念化:指定要素空间关系的定义方式,即空间权重关系; -
距离法:指定计算每个要素与邻近要素之间的距离的方式。选项包括欧氏距离以及曼哈顿距离; -
标准化:当要素的分布由于采样设计或施加的聚合方案而可能偏离时,建议使用行标准化; -
距离范围或距离阈值:为“反距离”和“固定距离”选项指定中断距离。将在对目标要素的分析中忽略为该要素指定的中断之外的要素。但是,对于“无差别的区域”,指定距离之外的要素的影响会随距离的减小而变弱,而在距离阈值之内的影响则被视为是等同的。


本篇文章来源于微信公众号: 码农设计师
{kind=link}