本系列配套练习数据下载链接:
链接:https://pan.baidu.com/s/1imKDcw9wZWk_ItR8fwugZw?pwd=mnsj提取码:mnsj
聚类分布制图工具集可通过执行聚类分析来识别具有统计显著性的热点、冷点和空间异常值的位置。这些工具在需要根据一个或多个聚类的位置执行某些行动时特别有用,例如在需要分配更多的警力来处理一组集中出现的入室盗窃案时,或者需要确定疾病爆发的地点以找到疾病根源的线索时。
聚类分布制图工具集包含聚类和异常值分析、分组分析、热点分析、优化的热点分析、优化的异常值分析、相似搜索六个工具。
本次主要介绍优化的热点分析工具。
-
1、概念:
优化的热点分析工具用于识别具有统计显著性的高值(热点)和低值(冷点)的空间聚类。优化的热点分析工具同样使用Getis-Ord Gi*统计,但增加了自动优化分析参数的功能,即优化的热点分析工具会对数据进行查询,从而获得产生最佳热点结果的设置。它自动聚合事件数据,识别适当的分析范围,并纠正多重测试和空间依赖性。该工具对数据进行查询,以确定可优化热点分析结果的设置。
如果要完全控制这些设置,可以改用热点分析工具。
关于热点分析(Getis-Ord Gi*)工具的相关内容可以查看以下文章:
【ArcGIS工具箱】127.聚类分布制图——热点分析(Getis-Ord Gi*)
-
数据要求和错误处理:如果输入的数据存在几何损坏、缺少几何信息,或者在指定的分析字段中有空值,这些记录将被视为错误,并且不会被纳入分析。为了确保结果的可靠性,当使用Getis-Ord Gi*统计时,至少需要30个要素。如果要素数量少于30,结果可能不可靠。 -
事件数据聚合:如果提供了代表事件的数据(没有特定分析字段),工具会对这些事件进行聚合,并使用事件的数量作为分析的值。聚合后,仍然需要至少有30个要素才能进行分析。对于事件数据,也需要超过30个要素才能开始聚合。 -
分析字段的要求:Gi*统计方法要求每个要素都有一个与之关联的值。这意味着,如果提供了分析字段,该字段中的值应该具有一定的变异性(即不是所有值都相同)。例如,该统计方法不适用于二进制数据(即只有两种可能值的数据)。 -
位置异常值的检测:位置异常值是指与数据集中的大多数要素相比,与邻近要素的距离远得多的要素。这些异常值可以对空间统计(如平均最近邻距离)产生显著影响。为了识别这些异常值,工具会计算每个要素的平均最近邻距离,并评估这些距离的分布。那些与最近的非重合邻近要素距离超过三个标准差距离的要素被视为位置异常值。
-
COUNT_INCIDENTS_WITHIN_FISHNET_POLYGONS/ COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS:计算合适的面像元大小,并利用所得结果创建渔网面网格或六边形面网格,该网格将固定在事件点上方,并将计算每个面像元内的点数。如果未提供定义事件潜在发生位置的边界面要素图层,则会删除不含点的像元,而仅分析剩余像元。如果提供边界面要素图层,则保留并分析边界面范围内的所有像元。每个面像元的点计数都将用作分析字段。 -
COUNT_INCIDENTS_WITHIN_AGGREGATION_POLYGONS:此方法需要事件点和预定义的聚合面(如行政区域、邮政编码区域等)。将这些聚合面与事件点进行叠加,然后计算每个聚合面内的事件点数量,并确保这些数量具有足够的差异性以进行分析。如果所有聚合面内的事件数量相同,则该方法不适用。 -
COUNT_INCIDENTS_WITHIN_HEXAGON_POLYGONS:需要提供用于将事件聚合到计数的面要素图层。此方法将计算每个面内的点事件数,然后对这些面及其相关计数进行分析。将计算捕捉距离并使用该距离聚合附近的事件点。将为每个聚合点提供一个计数,该计数反映捕捉到一起的事件数量。然后将此事件计数用作分析字段来分析这些聚合点。如果有许多重合点或接近重合的点,并且希望维护原始点数据空间模式的各个方面,则该选项是一项合适的聚合策略。
3、分析范围:
-
增量空间自相关:这个策略通过执行Global Moran’s I统计量来测量不同距离下的空间聚类程度。这个过程会排除位置异常值,并通过返回的z得分来确定聚类的程度。随着距离的增大,z得分通常也会增大,表示聚类程度增强。但在某些特定距离下,z得分可能达到峰值,这个峰值反映了最明显的空间聚类距离。优化的热点分析工具会寻找这个峰值距离作为分析范围。如果有多个峰值,会选择第一个。 -
K近邻平均距离:如果没有找到峰值距离,工具会检查要素的空间分布,并计算每个要素生成K个近邻的平均距离。K的值是输入要素数量的5%(或0.05*N),但会调整在3到30之间。如果生成K个近邻的平均距离超过一个标准距离,分析范围就设定为一个标准距离;否则,分析范围将基于这K个近邻的平均距离。 -
大型密集数据集的处理:对于包含500个或更多相邻要素的大型数据集,为了节省时间,将跳过增量空间自相关分析。而是直接计算能生成30个相邻要素的平均距离,并将其作为分析范围。
5、输出:
最后一部分是创建输出要素。如果输入要素表示需要聚合的事件数据,则输出要素将反映聚合的加权要素(渔网面或六边形面像元或为事件点聚合面参数提供的聚合面或加权点)。每个要素都具有 z 得分、p 值和 Gi Bin 结果以及每个要素在计算中所包括的相邻要素数。
-
2、工具:
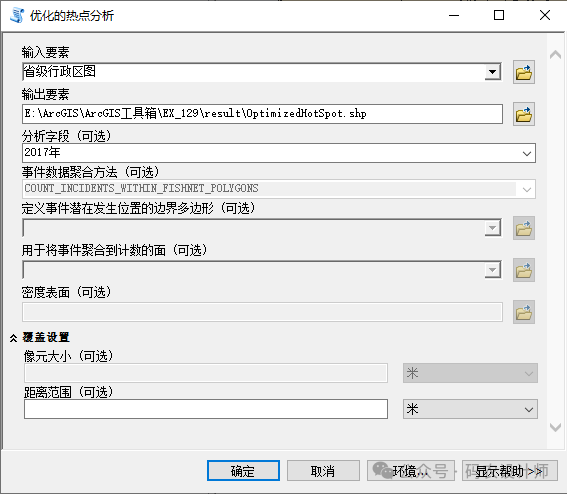
-
事件数据聚合方法:用于创建加权要素以通过事件点数据进行分析的聚合方法; -
定义事件潜在发生位置的边界多边形:代表了事件可能发生的地理区域。通过设置这个参数,用户可以限制热点分析的计算范围,使其仅在指定的边界多边形内进行; -
用于将事件聚合到计数的面:用于将事件聚合到计数的面要素。主要是指在进行热点分析前,将离散的事件数据(如点数据)聚合到特定的面要素中,以便进行进一步的空间统计分析。该参数允许用户指定如何将事件数据分配到各个地理区域(面)内,并统计每个区域内的事件数量; -
像元大小:设置用于聚合点数据的格网的大小。选择渔网格网或者六边形格网时定义; -
距离范围:在进行热点分析时考虑的邻近要素之间的最大距离。该参数对于确定哪些要素应该被包括在分析中,以及它们之间的空间关系如何影响分析结果至关重要。
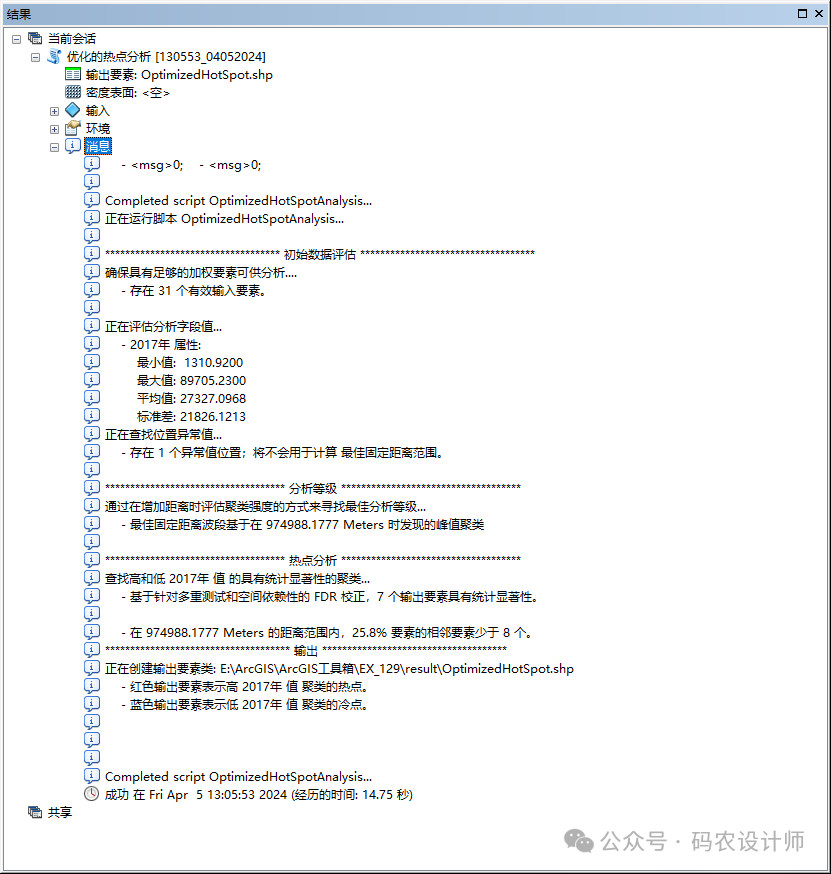
在工具执行期间,用于生成可优化热点分析结果的计算设置报告在结果窗口中:
以下分别是热点分析(Getis-Ord Gi*)工具和优化的热点分析工具的计算结果,可以看到两者还是有明显区别的:
| 热点分析工具 |
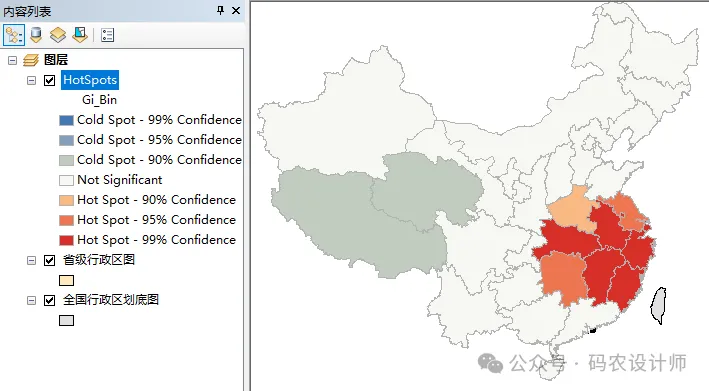 |
| 优化的热点分析工具 |
|
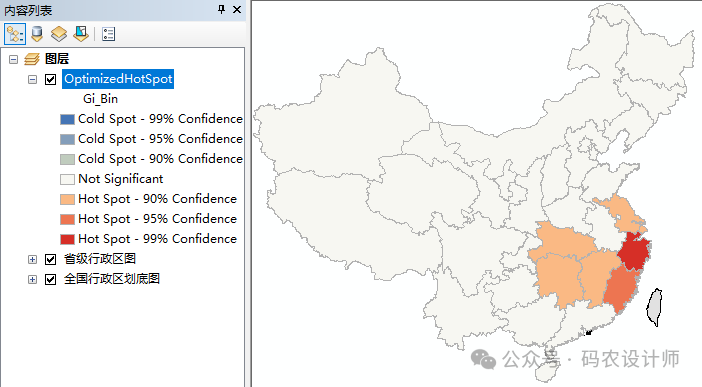
2、输入要素为点要素:
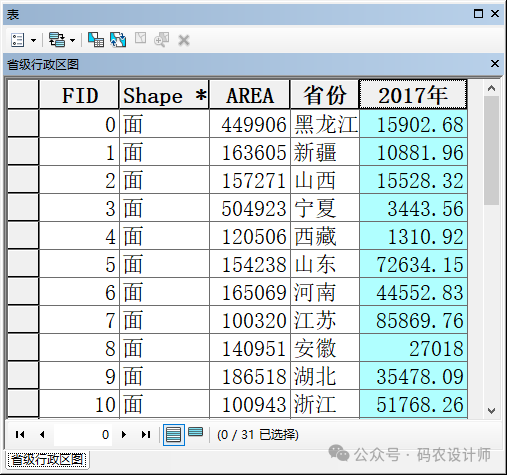
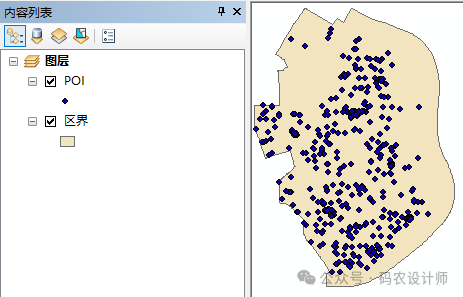
加载【POI】点要素,以及【区界】面要素。
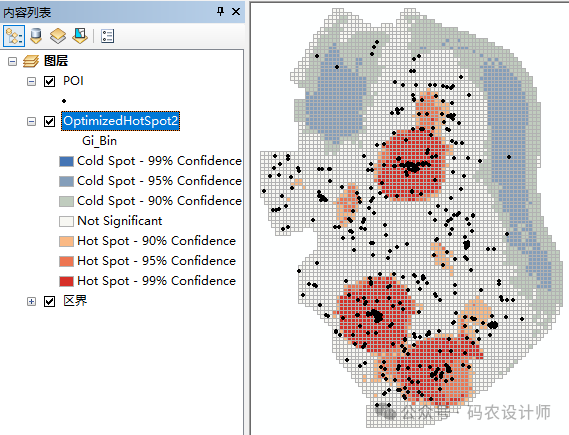
选择【系统工具箱→Spatial Statistics Tools→聚类分布制图→优化的热点分析】工具,在弹出的对话框中进行设置。
本次不提供分析字段,该工具会将聚合所有点以获得点计数,用作分析字段。


本篇文章来源于微信公众号: 码农设计师
{kind=link}