本系列配套练习数据下载链接:
链接:https://pan.baidu.com/s/1imKDcw9wZWk_ItR8fwugZw?pwd=mnsj提取码:mnsj
聚类分布制图工具集可通过执行聚类分析来识别具有统计显著性的热点、冷点和空间异常值的位置。这些工具在需要根据一个或多个聚类的位置执行某些行动时特别有用,例如在需要分配更多的警力来处理一组集中出现的入室盗窃案时,或者需要确定疾病爆发的地点以找到疾病根源的线索时。
聚类分布制图工具集包含聚类和异常值分析、分组分析、热点分析、优化的热点分析、优化的异常值分析、相似搜索六个工具。
本次主要介绍相似搜索工具。
-
1、概念:
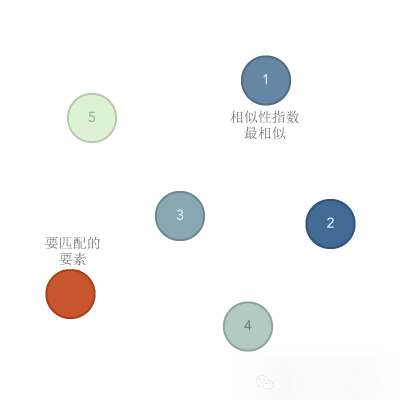
相似搜索工具用于根据要素属性来确定哪些候选要素与输入要素最相似或最不相似。
—————-
感兴趣属性用于相似性的比较的属性字段列表。
感兴趣属性值必须为数值,而且必须同时存在于要匹配的输入要素和候选要素数据集中(相同字段名和相同字段类型)。对于感兴趣属性参数,该工具将列出在要匹配的输入要素数据集中找到的所有数值字段。
3、最相似或最不相似:
用户可以选择搜索与输入要素最相似的候选要素,还是最不相似的要素,或者同时搜索两者。
-
MOST_SIMILAR:查找最相似的要素。 -
LEAST_SIMILAR:查找最不相似的要素。 -
BOTH:查找最相似的要素和最不相似的要素。
-
ATTRIBUTE_VALUES(属性值):
-
RANKED_ATTRIBUTE_VALUES(等级属性值):
-
ATTRIBUTE_PROFILES(属性剖面):


5、结果数:
定义工具应返回的相似或不相似的要素数量。
-
MATCH_ID:列出要匹配的输入要素图层中的所有目标要素,并将其 OID 或 FID 标识符写入该字段中。匹配解决方案在该字段的值为 NULL 。如果输出要素值为 shapefile,则 NULL 值将由很大的负数(例如 -21474836)来表示。 -
CAND_ID:列出所有的匹配解决方案,该值表示这些解决方案的 OID 或 FID 标识符。要匹配的输入要素图层中的目标要素在该字段的值为 NULL。如果输出要素值为 shapefile,则 NULL 值将由很大的负数(例如 -21474836)来表示。 -
SIMRANK(相似性等级):如果为匹配方法参数选择了 MOST_SIMILAR 或 BOTH,则所有匹配的解决方案均按照从最相似到最不相似的顺序进行等级划分。最相似匹配解决方案的等级值为 1。 -
DSIMRANK(相异性等级):如果为匹配方法参数选择了 LEAST_SIMILAR 或 BOTH,则所有匹配的解决方案均按照从最不相似到最相似的顺序进行等级划分。最不相似的解决方案的等级值为 1。 -
SIMINDEX(值平方差总和、等级平方差总和或余弦相似性):该字段量化了每个匹配解决方案与目标要素的相似程度。 -
LABELRANK(渲染等级):该字段仅用于显示。该工具使用该字段为分析结果提供默认渲染。
-
2、工具:
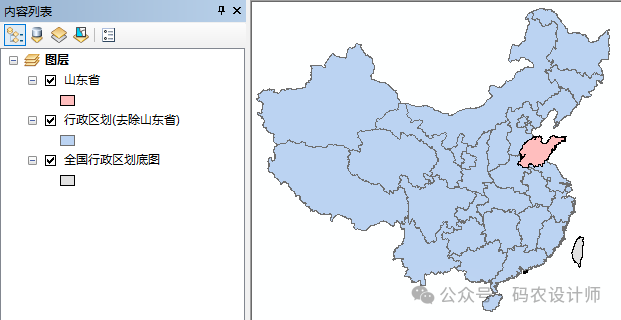
选择【系统工具箱→Spatial Statistics Tools→聚类分布制图→相似搜索】工具,在弹出的对话框中进行设置。
-
折叠输出转点:如果要匹配的输入要素和候选要素同时为线或面,可以选择是要将输出要素的几何折叠为点,还是使其与输入要素的原始几何(线或面)相匹配。选中时,线和面要素将表示为要素质心(点)。未选中时(默认设置),输出几何将与输入要素的线或面几何相匹配。 -
追加到输出的字段:包含输出要素的可选属性列表。可根据需要选择特定的字段(不用于确定相似性的字段),这些字段将在计算完成后添加到输出结果中。例如,包含名称标识符、分类字段或者日期字段。
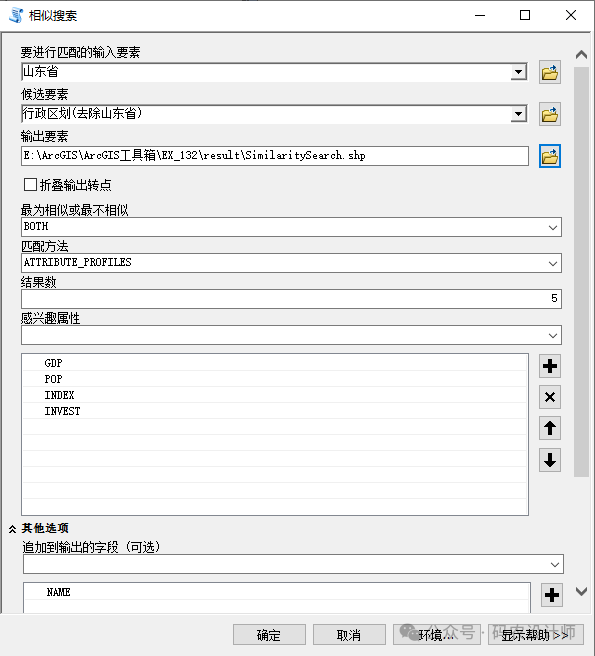
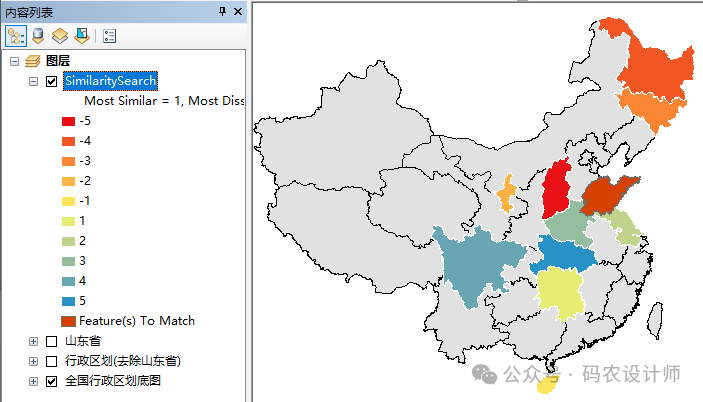
生成的包含相似度排名的表格数据:


本篇文章来源于微信公众号: 码农设计师
{kind=link}