本系列文章配套代码获取有以下三种途径:
-
可以在以下网站查看,该网站是使用JupyterLite搭建的web端Jupyter环境,因此无需在本地安装运行环境即可使用,首次运行浏览器需要下载一些配置文件(大约20M):
https://returu.github.io/Python_Data_Analysis/lab/index.html-
也可以通过百度网盘获取,需要在本地配置代码运行环境,环境配置可以查看【Python基础】2.搭建Python开发环境:
链接:https://pan.baidu.com/s/1MYkeYeVAIRqbxezQECHwcA?pwd=mnsj提取码:mnsj
-
前往GitHub详情页面,单击 code 按钮,选择Download ZIP选项:
https://github.com/returu/Python_Data_Analysis根据《Python for Data Analysis 3rd Edition》翻译整理
—————————————————–
统计和其他通过移动窗口或具有指数衰减而运行的函数是用于时间序列操作的数组变换的一个重要类别,这对平滑噪声或粗糙的数据非常有用,这些函数被称为移动窗口函数,尽管也包含一些没有固定长度窗口的函数,例如指数加权移动平均。
rolling 函数的行为类似于resample 和groupby。它可以在一个Series 或DataFrame 上通过一个窗口 window (以一个区间的数字表示)进行调用,但它不是直接分组,而是创建一个滑动窗口分组的对象。
1DataFrame.rolling(window,
2 min_periods=None,
3 center=False,
4 win_type=None,
5 on=None,
6 axis=0,
7 closed=None,
8 step=None,
9 method='single')-
window:表示时间窗的大小,有两种形式:①使用数值int,则表示观测值的数量,即向前几个数据;②也可以使用offset类型,这种类型较复杂,使用场景较少;
-
min_periods:每个窗口最少包含的观测值数量,小于这个值的窗口结果为NA。值可以是int,默认None。offset情况下,默认为1;
-
center: 把窗口的标签设置为居中,布尔型,默认False,居右
-
win_type: 窗口的类型。截取窗的各种函数。字符串类型,默认为None;
-
on: 可选参数。对于dataframe而言,指定要计算滚动窗口的列。值为列名。
-
axis: 默认为0,即对列进行计算
-
closed:定义区间的开闭,支持int类型的window。对于offset类型默认是左开右闭的即默认为right。可以根据情况指定为left、both等。
-
step:在每一步结果中评估窗口,相当于切片为[::step]。窗口必须是一个整数。使用None或1以外的step参数将产生一个与输入不同形状的结果。
-
method:在单个列或行(‘single’)或整个对象(‘table’)上执行rolling操作。该参数只有在方法调用中指定engine=’numba’时才会实现。
1>>> dates = pd.date_range('2022-1-3','2022-1-15')
2
3>>> df = pd.DataFrame(data = np.arange(len(dates)*2).reshape(-1,2) , columns=["data1","data2"],index=dates)
4>>> df
5 data1 data2
62022-01-03 0 1
72022-01-04 2 3
82022-01-05 4 5
92022-01-06 6 7
102022-01-07 8 9
112022-01-08 10 11
122022-01-09 12 13
132022-01-10 14 15
142022-01-11 16 17
152022-01-12 18 19
162022-01-13 20 21
172022-01-14 22 23
182022-01-15 24 25
19
20# 按照工作日频率进行重新采样
21>>> df = df.resample("B").ffill()
22>>> df
23 data1 data2
242022-01-03 0 1
252022-01-04 2 3
262022-01-05 4 5
272022-01-06 6 7
282022-01-07 8 9
292022-01-10 14 15
302022-01-11 16 17
312022-01-12 18 19
322022-01-13 20 21
332022-01-14 22 23
34
35# 获取一列数据
36>>> data = df["data1"]
37>>> data
382022-01-03 0
392022-01-04 2
402022-01-05 4
412022-01-06 6
422022-01-07 8
432022-01-10 14
442022-01-11 16
452022-01-12 18
462022-01-13 20
472022-01-14 22
48Freq: B, Name: data1, dtype: int32
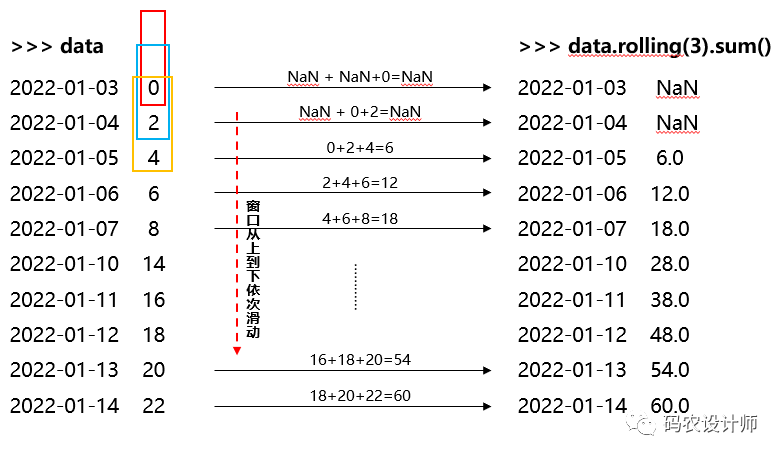
表达式rolling(3)相当于创建了一个长度为3的窗口window,然后窗口从上到下依次滑动,然后再调用sum()函数,对每个窗口内的元素求和,进而输出结果。
1>>> data.rolling(3).sum()
22022-01-03 NaN
32022-01-04 NaN
42022-01-05 6.0
52022-01-06 12.0
62022-01-07 18.0
72022-01-10 28.0
82022-01-11 38.0
92022-01-12 48.0
102022-01-13 54.0
112022-01-14 60.0
12Freq: B, Name: data1, dtype: float64
上述操作过程如图所示:
除了sum()函数,还支持很多函数,例如:
-
count() 非空观测值数量;
-
mean() 值的均值;
-
median() 值的算术中值;
-
min() 最小值;
-
max() 最大;
-
std() 贝塞尔修正样本标准差;
-
var() 无偏方差;
-
skew() 样品偏斜度(三阶矩);
-
kurt() 样品峰度(四阶矩);
-
quantile() 样本分位数(百分位上的值);
-
cov() 无偏协方差(二元);
-
corr() 相关性(二进制)。
-
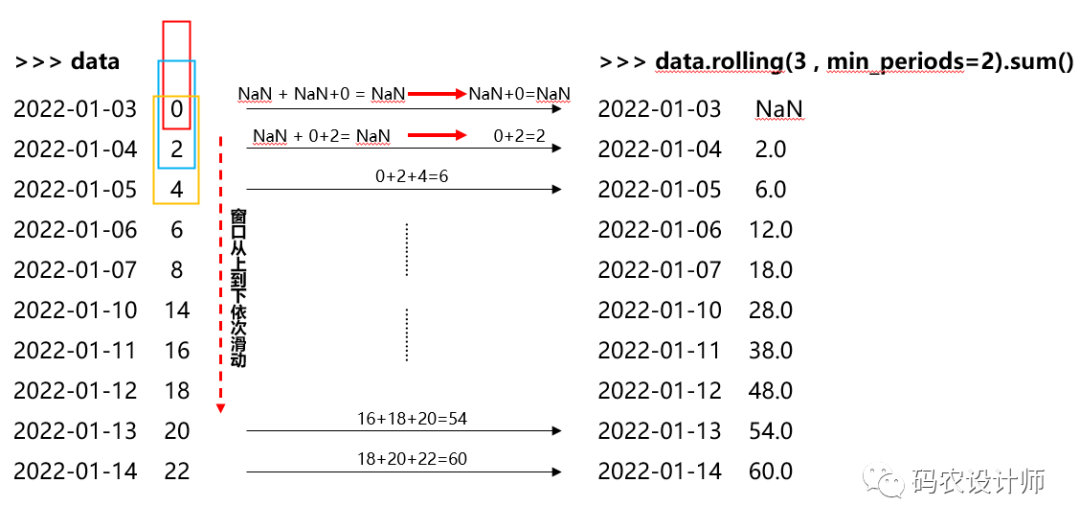
min_periods参数
1>>> data.rolling(3 , min_periods=2).sum()
22022-01-03 NaN
32022-01-04 2.0
42022-01-05 6.0
52022-01-06 12.0
62022-01-07 18.0
72022-01-10 28.0
82022-01-11 38.0
92022-01-12 48.0
102022-01-13 54.0
112022-01-14 60.0
12Freq: B, Name: data1, dtype: float64
上述操作过程如图所示:
-
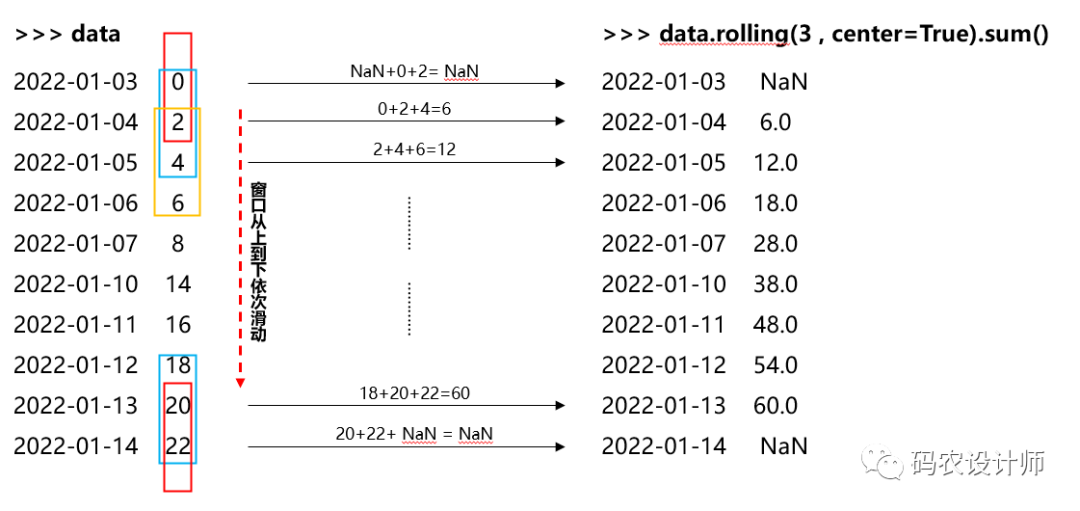
center参数
1>>> data.rolling(3 , center=True).sum()
22022-01-03 NaN
32022-01-04 6.0
42022-01-05 12.0
52022-01-06 18.0
62022-01-07 28.0
72022-01-10 38.0
82022-01-11 48.0
92022-01-12 54.0
102022-01-13 60.0
112022-01-14 NaN
12Freq: B, Name: data1, dtype: float64
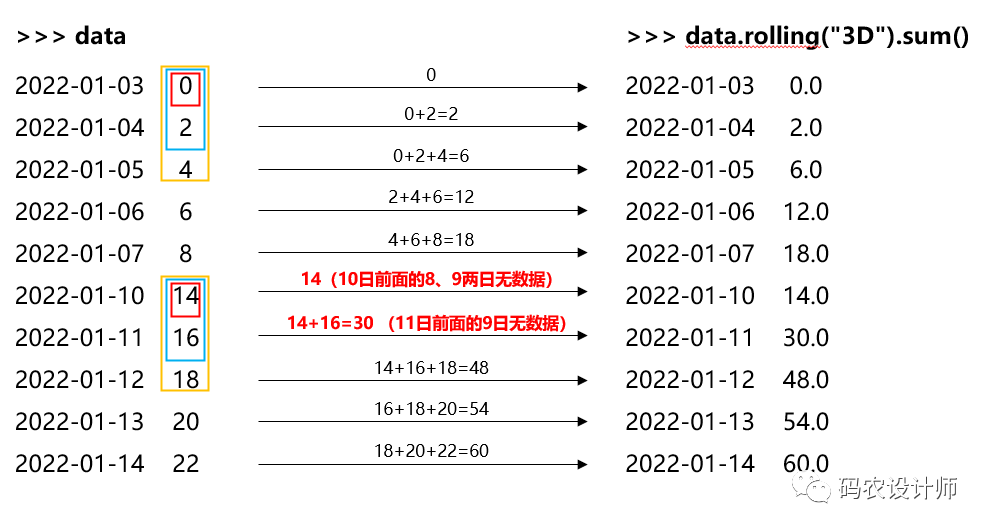
1>>> data.rolling("3D").sum()
22022-01-03 0.0
32022-01-04 2.0
42022-01-05 6.0
52022-01-06 12.0
62022-01-07 18.0
72022-01-10 14.0
82022-01-11 30.0
92022-01-12 48.0
102022-01-13 54.0
112022-01-14 60.0
12Freq: B, Name: data1, dtype: float64
上述操作过程如图所示:
1>>> df.rolling(3).sum()
2 data1 data2
32022-01-03 NaN NaN
42022-01-04 NaN NaN
52022-01-05 6.0 9.0
62022-01-06 12.0 15.0
72022-01-07 18.0 21.0
82022-01-10 28.0 31.0
92022-01-11 38.0 41.0
102022-01-12 48.0 51.0
112022-01-13 54.0 57.0
122022-01-14 60.0 63.0
expanding函数的功能为滚动计算。类似rolling函数,区别在于在rolling函数中“取数框”中的滚动计算数据是固定的,而expanding函数,从时间序列的起始位置开始时间窗口,并增加窗口的大小,直到它涵盖整个序列,进行累计运算。
1DataFrame.expanding(min_periods=1, center=None, axis=0, method='single')
1>>> data
22022-01-03 0
32022-01-04 2
42022-01-05 4
52022-01-06 6
62022-01-07 8
72022-01-10 14
82022-01-11 16
92022-01-12 18
102022-01-13 20
112022-01-14 22
12Freq: B, Name: data1, dtype: int32
13
14>>> data.expanding(min_periods=3).sum()
152022-01-03 NaN
162022-01-04 NaN
172022-01-05 6.0
182022-01-06 12.0
192022-01-07 20.0
202022-01-10 34.0
212022-01-11 50.0
222022-01-12 68.0
232022-01-13 88.0
242022-01-14 110.0
25Freq: B, Name: data1, dtype: float64
-
故前两行数据为NaN; -
第三行数据:0(第一行)+2(第二行)+4(第三行)=6; -
第四行数据:0(第一行)+2(第二行)+4(第三行)+6(第四行)=12; -
以此类推……

本篇文章来源于微信公众号: 码农设计师
{kind=link}