本系列文章配套代码获取有以下两种途径:
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1XuxKa9_G00NznvSK0cr5qw?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/PyTorchTensorBoard:
https://tensorflow.google.cn/tensorboard?hl=zh-cnPyTorch1.1.0版本之后就内置了TensorBoard的相关接口,因此可以直接在PyTorch中使用TensorBoard。以下是TensorBoard的主要使用场景:
-
训练过程可视化:TensorBoard可以展示模型训练过程中的各项指标,如损失值、准确率等,从而帮助开发者实时监控模型的训练进展。 -
模型结构可视化:通过TensorBoard,开发者可以清晰地看到模型的计算图,包括各层的连接关系和参数数量,这有助于更好地理解模型的结构。 -
数据分布可视化:TensorBoard能够展示模型输入数据以及权重、偏差或其他张量的分布情况,使开发者能够更深入地了解数据的特征和分布。 -
嵌入向量可视化:对于包含嵌入向量的模型(如Word2Vec),TensorBoard可以将这些嵌入向量可视化为二维或三维空间中的点,便于观察和理解嵌入向量之间的关系。
-
安装TensorBoard:
pip install tensorboard
-
配置TensorBoard:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('
-
记录训练数据:
for epoch in range(n_epochs):
# 假设loss是当前批次的损失
writer.add_scalar('Loss', loss.item(), epoch)
......
-
启动TensorBoard:
tensorboard --logdir=<directory_name>
-
查看结果:
https://pytorch.org/docs/stable/tensorboard.html
记录标量:
add_scalar(tag,
scalar_value,
global_step=None,
walltime=None,
new_style=False,
double_precision=False)
-
tag: 字符串参数,用于标识所记录数据的标签。在TensorBoard界面中,这个标签用来区分不同的数据序列,比如你可以用 “Loss/train” 来标记训练损失,用 “Accuracy/validation” 标记验证精度。良好的标签命名习惯对于后期分析非常重要。 -
scalar_value: 实际要记录的标量数值,可以是任何浮点数,用于表示训练过程中的某个度量标准(如损失值、准确率等)。 -
global_step: 可选参数,表示记录该标量值时的全局步数。通常对应当前的训练步数或迭代次数。通过提供这个值,你可以在 TensorBoard 中跟踪标量值随训练步骤的变化。 -
walltime: 可选参数,代表记录标量值时的实际时间(通常是 Unix 时间戳)。如果你不提供这个值,TensorBoard 会使用当前时间来代替。 -
new_style: 这是一个布尔标志,指示是否使用新的TensorBoard数据格式。在较新版本的TensorBoard中,该参数可能已经不再需要,因为新版本通常默认使用更新、更高效的数据记录方式。旧版API中可能会出现这个选项,但现在通常无需手动设置。 -
double_precision: 指示是否以双精度(64位浮点数)存储标量值。默认情况下,大多数实现可能使用单精度(32位浮点数)存储以节省空间。如果你的标量值需要更高的精度,可以设置此参数为True。注意,这可能增加存储空间的消耗。
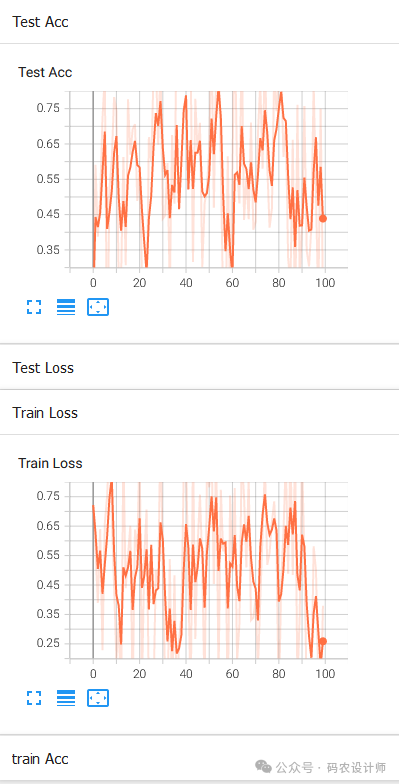
# 初始化TensorBoard的记录器
logger = SummaryWriter(log_dir = 'run')
# 使用add_scalar记录标量
for n_iter in range(100):
logger.add_scalar('Train Loss' , np.random.random() , n_iter)
logger.add_scalar('Test Loss' , np.random.random() , n_iter)
logger.add_scalar('train Acc' , np.random.random() , n_iter)
logger.add_scalar('Test Acc' , np.random.random() , n_iter)
显示直方图:
add_histogram(tag,
values,
global_step=None,
bins='tensorflow',
walltime=None,
max_bins=None)
其中:
-
tag : 直方图的标签名,这个名称将在 TensorBoard 中用于标识和显示这个直方图。 -
values : 包含要记录为直方图的数据的数组。这通常是一个数值型数组,比如从模型的权重、梯度或其他需要监控的分布中抽取的样本。 -
global_step: 与add_scalar()相同。 -
bins : 控制直方图的分箱方式。如果是字符串,包含以下选项 ‘tensorflow’(默认值)、‘auto’、‘fd’(Freedman Diaconis Estimator)、‘doane’、‘scott’ 或 ‘rice’ 等,这些选项对应不同的自动分箱策略。如果是整数数组,它定义了手动设置的分箱边界。 -
walltime :与add_scalar()相同。 -
max_bins: 直方图中最大的箱子数量,以防数据分布极广时生成过多的箱,导致内存消耗过大或图形难以解读。如果 bins 参数是一个整数数组,这个参数将被忽略。
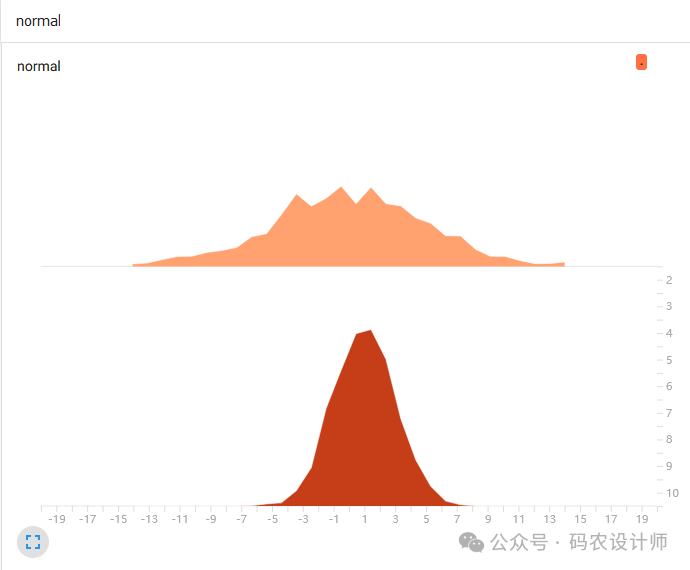
# 使用add_histogram显示直方图
logger.add_histogram('normal' , np.random.normal(0,5,1000) , global_step=1)
logger.add_histogram('normal' , np.random.normal(1,2,1000) , global_step=10)
显示图像:
TensorBoard 允许用户将图像数据写入的日志文件,以便在 TensorBoard 中进行可视化。这对于可视化模型的输出、中间特征图或者任何与训练、测试过程相关的图像数据都非常有帮助。
-
add_image()方法:
add_image方法用于添加单张图像到TensorBoard中。它适用于想要单独展示某个特定图像或某一时刻模型输出的情况。
add_image(tag,
img_tensor,
global_step=None,
walltime=None,
dataformats='CHW')-
tag: 用于标识图像的标签,这个名称将在 TensorBoard 中用于标识和显示这个图像。 -
img_tensor : 要记录的图像数据。张量的形状和数值类型取决于 dataformats 参数的设置。通常,这是一个浮点张量,其值范围在 0 到 1 之间,表示图像的像素值。 -
global_step : 与add_scalar()相同。 -
walltime: 与add_scalar()相同。 -
dataformats : 指定图像数据的维度顺序。默认为‘CHW’,即通道(Channel)、高度(Height)、宽度(Width)的顺序。如果数据格式不同,例如是‘HWC’(高度、宽度、通道),需要相应地调整此参数。
例如,将一个批次的MNIST数据集图像组合成一个网格图像并在TensorBoard 中进行可视化(关于torchvision.utils.make_grid方法的介绍可以在文章最后的附录部分查看):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,),(0.5,))
])
dataset = datasets.MNIST('data/' , download=True , train=False , transform=transform)
dataloader = DataLoader(dataset , shuffle=True , batch_size=16)
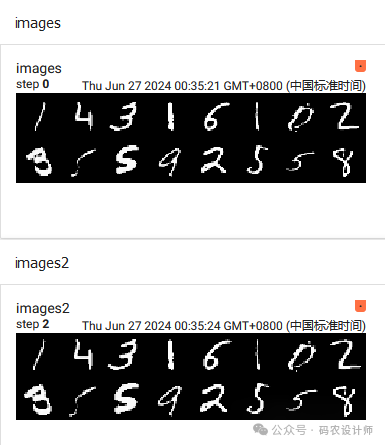
images,labels = next(iter(dataloader))
# 将一批图像组合成一个网格图像
grid = torchvision.utils.make_grid(images)
# 使用add_image显示图像
logger.add_image('images' , grid , 0)
-
add_images()方法:
add_images(tag,
img_tensor,
global_step=None,
walltime=None,
dataformats='NCHW')
# 直接使用add_images显示一批次图像
logger.add_images('images2' , images , 2)
可视化效果如下图所示:
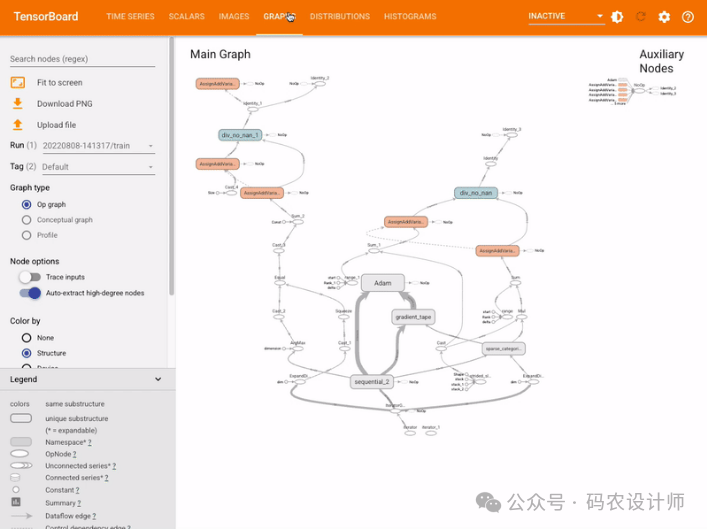
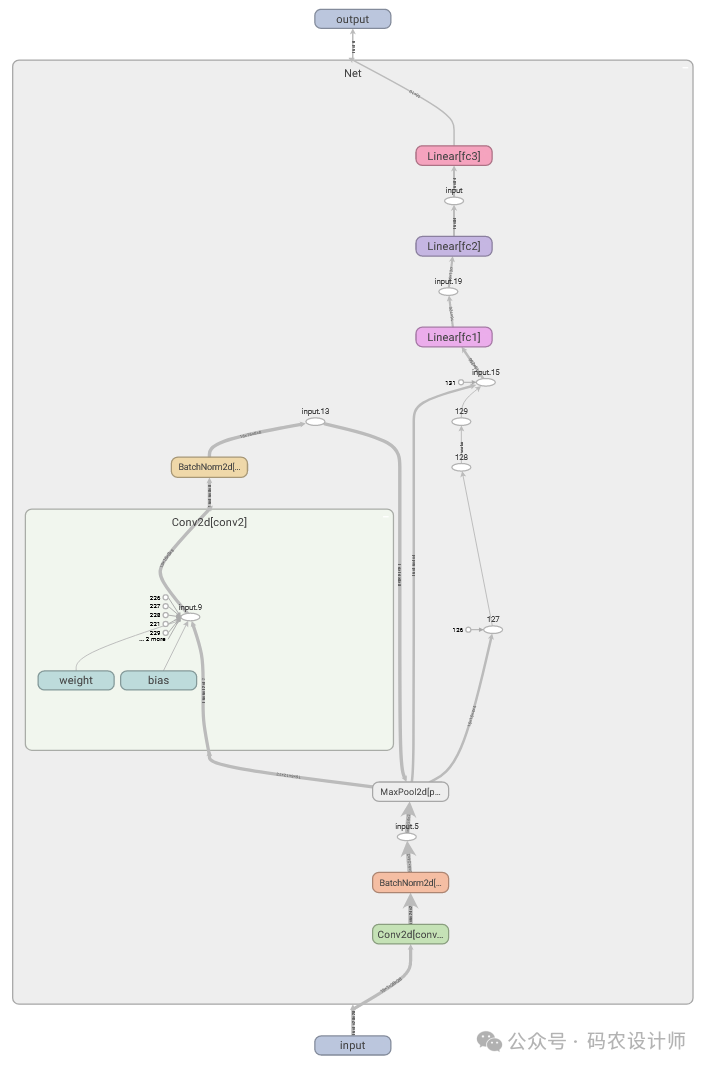
显示网络结构:
add_graph()方法是TensorBoard中的一个功能,用于可视化模型的计算图结构。这一功能允许用户在TensorBoard界面中直观地查看神经网络模型的组成,包括层与层之间的连接、操作(ops)以及数据流动的方向。这对于理解模型架构、排查错误以及优化模型设计非常有帮助。
add_graph(model,
input_to_model=None,
verbose=False,
use_strict_trace=True)
-
model: 要可视化的神经网络模型对象。 -
input_to_model: 张量或张量元组,表示模型的输入数据。这个参数是可选的,但如果你不提供它,add_graph 可能会使用一个随机生成的张量作为输入。通常,为了获得更准确的计算图,建议使用实际的输入数据。 -
verbose: 布尔值,指示是否在构建图时打印详细信息。如果设置为 True,add_graph 会在控制台输出额外的调试信息,有助于了解图构建的过程。 -
use_strict_trace: 布尔值,决定是否使用严格的跟踪模式。在 PyTorch 1.9.0 之前,add_graph 使用的是 torch.jit.trace 来捕获模型的操作。从 PyTorch 1.9.0 开始,默认情况下 add_graph 使用 torch.jit.trace_module来提供一个更准确的图表示,尤其是在处理控制流(如条件语句和循环)时。如果设置为 False,则使用旧的跟踪方法。
例如,使用 add_graph可视化自定义的卷积神经网络模型的结构:
# 定义网络
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.bn1 = nn.BatchNorm2d(6)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.bn2 = nn.BatchNorm2d(16)
self.fc1 = nn.Linear(16 * 4 * 4, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(nn.functional.relu(self.bn1(self.conv1(x))))
x = self.pool(nn.functional.relu(self.bn2(self.conv2(x))))
x = x.view(x.size(0), -1)
x = nn.functional.relu(self.fc1(x))
x = nn.functional.relu(self.fc2(x))
x = self.fc3(x)
return x
model = Net()
# 使用add_graph可视化网络结构
logger.add_graph(model , images)
可视化效果如下图所示:
可视化embedding:
add_embedding(mat,
metadata=None,
label_img=None,
global_step=None,
tag='default',
metadata_header=None)
其中:
-
mat:形状为 [N, D] 的张量,其中 N 是嵌入向量的数量,D 是嵌入向量的维度。 -
metadata:包含元数据的列表,长度为 N,与 mat 中的嵌入向量一一对应。元数据可以是任何描述嵌入向量额外信息的字符串列表,例如单词或标签。这些元数据将在 TensorBoard 中与嵌入向量一同显示。 -
label_img:形状为 [N, C, H, W] 的张量,其中 C 是通道数,H 和W 是图像的高度和宽度。这个参数可选,用于为每个嵌入向量提供一个对应的图像标签。这在进行图像相关的嵌入可视化时特别有用。 -
global_step:与add_scalar()相同 -
tag:字符串,用于在 TensorBoard 中标识这组嵌入向量。默认值为 ‘default’。 -
metadata_header:字符串或字符串列表,用于描述元数据的格式或内容。这个参数是可选的,但如果你提供了元数据,这个参数可以帮助你更好地理解和解释这些元数据。
dataset = datasets.MNIST('data/' , download=True , train=False)
images = dataset.data[:50].float()
labels = dataset.targets[:50]
features = images.view(50,28*28)
# 使用add_embedding进行embedding可视化
logger.add_embedding(features , metadata=labels , label_img = images.unsqueeze(1) , global_step =10)
可视化效果如下图所示:

附录:make_grid():
torchvision.utils.make_grid 是一个用于将一批图像组合成一个网格图像的函数,这在可视化和调试深度学习模型时特别有用。
torchvision.utils.make_grid(tensor,
nrow,
padding,
normalize,
value_range,
scale_each,
pad_value)
-
tensor: 输入的图像张量或图像张量列表。每个图像张量都应该是C x H x W的形状,其中C是通道数,H是图像高度,W是图像宽度。如果输入是列表,则列表中的每个元素都应是一个图像张量。 -
nrow: 指定网格中每行的图像数量。根据这个参数和总图像数量,函数会自动计算出网格的行数。 -
padding: 图像之间以及图像边缘的填充像素数量。用于控制相邻图像之间的空白间隔大小。 -
normalize: 是否对图像进行归一化处理。如果设置为True,则函数会将图像张量中的值归一化到[0, 1]范围内(如果value_range未指定)。这通常用于确保图像在可视化时具有合适的亮度和对比度。 -
value_range: 包含两个整数的元组,表示图像数据值的范围。这个范围用于在normalize=True时,将图像数据归一化到[0, 1]区间。如果未指定,且normalize=True,则函数会尝试自动确定数据的范围。 -
scale_each:是否单独缩放每张图像。如果设置为True,则每张图像都会根据其自身的最小值和最大值进行缩放。这有助于在图像具有不同亮度范围时更好地进行可视化。 -
pad_value: 用于填充空白区域的颜色值。当padding大于0时,这些空白区域会填充这个值。
import torch
import torchvision
import matplotlib.pyplot as plt
# 假设 images 是一个形状为 (batch_size, C, H, W) 的张量
# ...
# 使用 make_grid 组合图像
grid = torchvision.utils.make_grid(images, nrow=5)
# 将张量转换为 numpy 数组并显示
plt.imshow(grid.permute(1, 2, 0))
# plt.show()
可视化效果如下图所示:

更多内容可以前往官网查看:
https://pytorch.org/


本篇文章来源于微信公众号: 码农设计师
{kind=link}