本系列配套练习数据下载链接:
链接:https://pan.baidu.com/s/1imKDcw9wZWk_ItR8fwugZw?pwd=mnsj提取码:mnsj
分析模式工具集能够提供对宏观空间模式进行量化的统计数据。这意味着,通过这些工具,可以将地理空间中的模式或趋势(例如,空间聚类的存在与否以及聚类程度的动态变化等)转换为具体的数值或指标,从而更客观地理解和分析这些数据。
分析模式工具集包含平均最近邻、高/低聚类、增量空间自相关、多距离空间聚类分析(Ripley’s K 函数)、空间自相关(Morans I)五个工具。
本次主要介绍多距离空间聚类分析(Ripley’s K 函数)工具。
-
1、概念:
多距离空间聚类分析(Ripley’s K 函数)工具用于确定要素(或与要素相关联的值)是否在给定的距离范围内显示具有统计显著性的聚类或离散。这个工具可以帮助理解空间数据的分布模式,特别是是否存在聚集或分散现象。
对于线和面要素,距离计算中会使用要素的质心。对于多点、折线或由多部分组成的面,将会使用所有要素部分的加权平均中心来计算质心。点要素的加权项是 1,线要素的加权项是长度,而面要素的加权项是面积。
—————-
-
ExpectedK:这是预期K值,它是根据距离值计算出来的理论上的K值。在Ripley’s K函数中,预期K值通常与距离值相匹配,作为一个基准来比较实际观察到的空间分布。 -
ObservedK:这是观察到的K值,它是从实际的空间数据中计算得出的。ObservedK反映了在给定距离尺度上,空间要素的实际聚集程度。 -
DiffK:这是观察到的K值与预期K值之间的差值。DiffK提供了实际空间分布与随机分布之间的差异度量。如果DiffK为正且较大,表明在该距离尺度上要素的聚集程度高于随机分布;如果DiffK为负,则表明要素分布相对离散。
-
LwConfEnv:低值置信区间(Lower Confidence Envelope)的缩写。如果ObservedK低于LwConfEnv,那么可以认为在该距离上的空间离散具有统计显著性。 -
HiConfEnv:高值置信区间(Higher Confidence Envelope)的缩写。如果ObservedK高于HiConfEnv,那么可以认为在该距离上的空间聚类具有统计显著性。
置信区间的计算:
– 如果未指定权重字段,则可通过在研究区域中随机分布点并计算该分布的 L(d) 来构建置信区间。点的每个随机分布称为一个“排列”。例如,如果选择了 99_PERMUTATIONS,则在每次迭代时,该工具均会将一组点随机分布 99 次。将这些点分布 99 次之后,该工具会对每个距离选择相对 k 观察值向上和向下偏离最大的 k 值;这些值将成为置信区间。
– 如果指定了权重字段,仅会对权重值进行随机重新分配来计算置信区间;点位置则保持固定。其实,指定“权重字段”时,位置会保持固定,并且该工具会评估空间中要素值的聚类。但如果未指定“权重字段”,则工具将分析要素位置的聚类/离散。
ArcMap官方文档
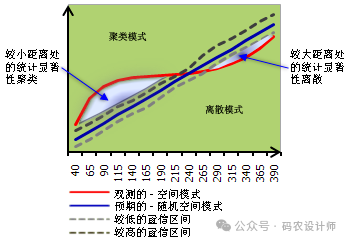
另外,启用以图形方式显示结果参数可以创建汇总工具结果的折线图。预期结果以蓝线表示,而观测结果则以红线表示。观测线在预期线之上表明数据集在该距离内表现为聚类。观测线在预期线之下表明数据集在该距离内表现为离散。折线图以图层方式创建。这些图层是临时图层,会在关闭 ArcMap 时被删除。右键单击该图层并选择保存,该图表会被写入到“图表文件”。如果在保存图表后保存地图文档,则此图表文件的链接会通过 .mxd 保存。
—————-
在多距离空间聚类分析(Ripley’s K 函数)工具中,边界校正方法是一个重要的参数。这个参数用于处理分析区域边界对数据的影响,因为在空间分析中,研究区域的边界可能会对统计结果产生偏差。边界校正方法的选择会影响K函数的计算结果,特别是当数据点接近研究区域边界时。该参数有以下可选项:
-
NONE:
-
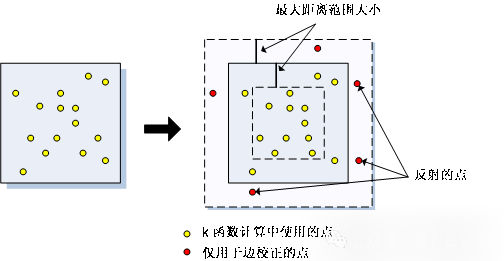
SIMULATE_OUTER_BOUNDARY_VALUES:
—————-
-
REDUCE_ANALYSIS_AREA:
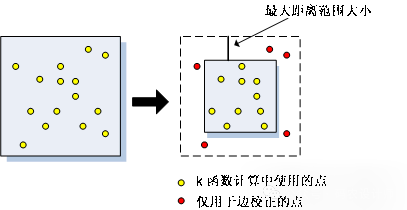
此边校正技术将分析区域的大小收缩一定的距离,此距离与将在分析中使用的最大距离范围相等。收缩研究区域后,仅在为仍处于研究区域内的点评估相邻点数目时,才会考虑新研究区域外发现的点。K 函数计算期间,不会以任何其他方式使用这些点。下图说明哪些点用于计算以及哪些点仅用于边校正。
—————-
-
RIPLEY’S_EDGE_CORRECTION_FORMULA:
此方法检查每个点与研究区域的边的距离以及这个点到其各相邻点的距离。如果有的相邻点与所涉及点的距离比与研究区域的边的距离更远,则所有这类相邻点都将被指定额外权重。此边校正方法仅适用于形状为正方形或矩形的研究区域,或者当为研究区域方法参数选择 MINIMUM_ENCLOSING_RECTANGLE 时才适用。
如果未应用边界校正,则统计缺漏偏差会随分析距离的增加而增加。如果启用以图形方式显示结果参数,会发现ObservedK线会在距离较大时下降。
-
2、工具:
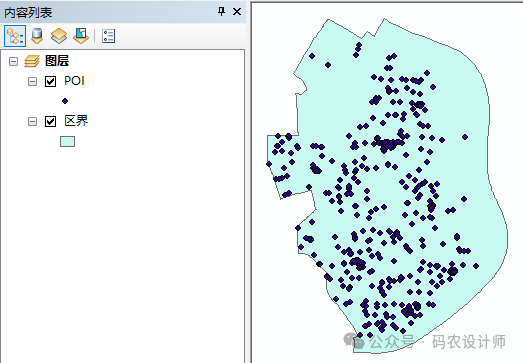
-
距离段数量:针对聚类而递增邻域大小和分析数据集的次数。分别在开始距离和距离增量参数中指定的增量的起点和大小。 -
开始距离、距离增量:如果未指定开始距离或距离增量,则将基于输入要素类的范围计算默认值——首先以围绕输入要素的最小外接矩形的最大范围长度的 25% 作为最大距离值。如果边界校正方法为 REDUCE_ANALYSIS_AREA,则将最大距离设为最大范围长度的 25% 与最小外接矩形最小范围长度的 50% 之中的较大者。如果提供了开始距离,距离增量为(最大距离 – 开始距离)/迭代值。如果没有提供开始距离,距离增量为最大距离/迭代值,开始距离则设为“距离增量”值。 -
计算置信区间:置信区间通过将要素点(或要素值)随机放在研究区域中计算。随机放置的点/值的数量与要素类中的点的数量相同。每组随机放置都称为“排列”,置信区间就通过这些排列创建。此参数用于选择要使用多少排列来创建置信区间。 -
以图形方式显示结果:指定工具是否将创建图层汇总结果。 -
权重字段:最适用于表示事件数或计数。如果未指定权重字段,则最大 DiffK 值将表明促进空间聚类的过程最明显的距离。 -
边界校正方法:对于研究区域的边附近要素的相邻点数低估情况进行校正所采用的方法。 -
研究区域方法:指定要用于研究区域的区域。K 函数对研究区域大小的变化很敏感,因此认真选择此值很重要。 -
研究区域要素类:描绘应在其中分析输入要素类的区域的要素类。如果未指定研究区域,此工具会使用最小外接矩形作为研究区域面。仅在研究区域方法参数选择了 USER_PROVIDED_STUDY_AREA_FEATURE_CLASS 时需要指定。如果指定了研究区域要素类,则应只具有一个单部分要素(研究区域面)。
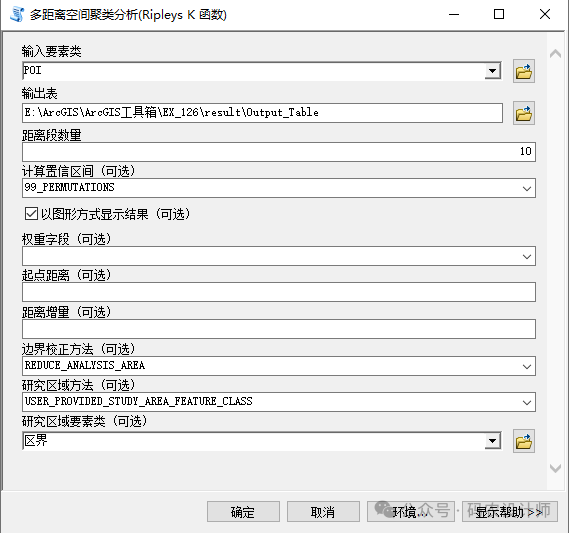
生成一个包含多个字段的输出表格:
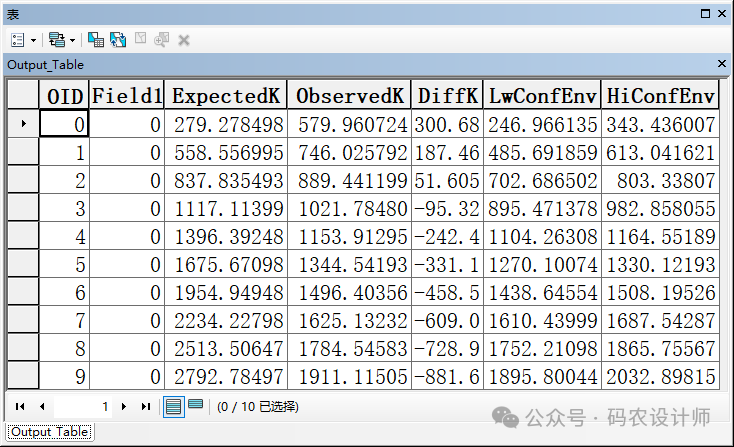
还将创建一个汇总工具结果的折线图:
图表显示在较小距离处的统计显著性聚集,在较大距离处的统计显著性离散。


本篇文章来源于微信公众号: 码农设计师
{kind=link}