本系列配套练习数据下载链接:
链接:https://pan.baidu.com/s/1imKDcw9wZWk_ItR8fwugZw?pwd=mnsj提取码:mnsj
聚类分布制图工具集可通过执行聚类分析来识别具有统计显著性的热点、冷点和空间异常值的位置。这些工具在需要根据一个或多个聚类的位置执行某些行动时特别有用,例如在需要分配更多的警力来处理一组集中出现的入室盗窃案时,或者需要确定疾病爆发的地点以找到疾病根源的线索时。
聚类分布制图工具集包含聚类和异常值分析、分组分析、热点分析、优化的热点分析、优化的异常值分析、相似搜索六个工具。
本次主要介绍聚类和异常值分析 (Anselin Local Moran’s I)工具。
-
1、概念:
聚类和异常值分析 (Anselin Local Moran’s I)工具用于识别数据中的空间聚类(即相似值的区域聚集)和空间异常值(与周边区域显著不同的值)。
-
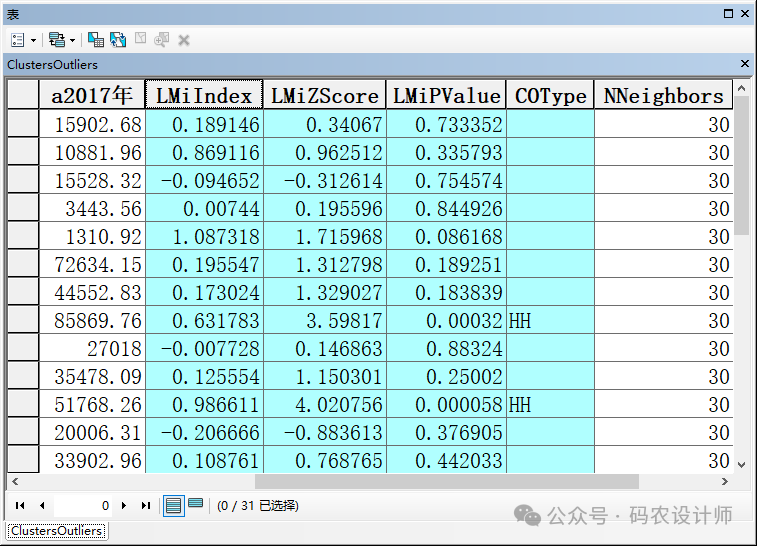
Local Moran’s I值:是一个局部空间自相关的度量指标。该指数衡量一个特定空间单元(如一个地理区域)与其相邻单元之间属性值的相似程度。正值表示该空间单元的属性值与相邻单元的属性值相似,即存在正的空间自相关,可能意味着聚类或集中现象。负值则表示该空间单元的属性值与相邻单元的属性值不同,即存在负的空间自相关,可能指示一个异常值或空间上的分散现象。绝对值大小反映了空间自相关的强度。 -
z得分:是Local Moran’s I指数的标准化形式,它表示Local Moran’s I值与期望值之间的差异,以标准差为单位来衡量。高的正z得分意味着观测到的Local Moran’s I值远高于随机模式下的期望值,指示强烈的空间聚类。低的负z得分则表示观测值远低于期望值,可能表示一个空间异常或分散的模式。 -
伪p值:用于评估Local Moran’s I统计量的统计显著性,即观察到的空间模式是否可能由随机过程产生。一个较小的伪 p 值(通常阈值设为0.05或更小)表明,观察到的Local Moran’s I值不太可能是随机的,因此该空间模式具有统计显著性。 -
聚类/异常值类型(COType):根据Local Moran’s I值、z得分和p值,将每个空间单元分类为不同类型的聚类(如高值聚类HH或低值聚类LL)或异常值(如高值被低值围绕HL或低值被高值围绕LH)。COType 字段将始终指明置信度为 95% 的统计显著性聚类和异常值。只有统计显著性要素在 COType 字段中具有值。
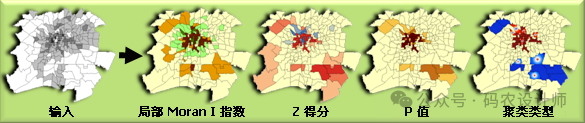
—————-
-
2、工具:
-
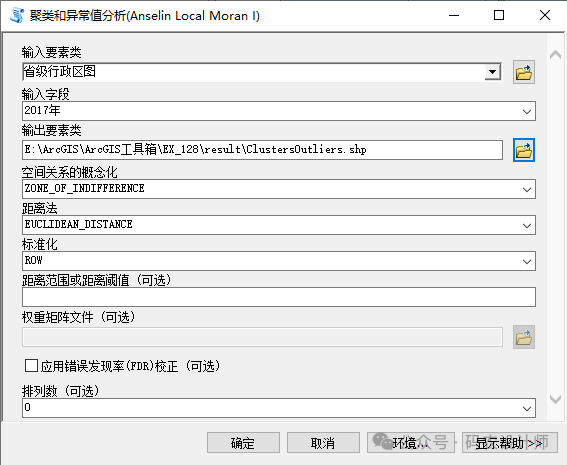
输入字段:用于计算的数值字段。输入字段应包含多种值。此统计数学方法要求待分析的变量存在一定程度的变化;例如,如果所有输入都是 1 便无法求解; -
空间关系的概念化:指定要素空间关系的定义方式,即空间权重关系; -
距离法:指定计算每个要素与邻近要素之间的距离的方式。选项包括欧氏距离以及曼哈顿距离; -
距离范围或距离阈值:为“反距离”和“固定距离”选项指定中断距离。将在对目标要素的分析中忽略为该要素指定的中断之外的要素。但是,对于“无差别的区域”,指定距离之外的要素的影响会随距离的减小而变弱,而在距离阈值之内的影响则被视为是等同的; -
标准化:当要素的分布由于采样设计或施加的聚合方案而可能偏离时,建议使用行标准化; -
应用错误发现率(FDR)校正:指定在评估统计显著性时是否使用 FDR 校正。选中时,统计显著性将以置信度为 95% 的错误发现率校正为基础。未选中(默认设置)时, p 值小于 0.05 的要素将显示在 COType 字段中,反映置信度为 95% 的统计显著性聚类或异常值; -
排列数:排列可用于确定找到您所分析值的实际空间分布的可能性。对于各个排列而言,各要素周围的邻域值将随机进行重新排列,并会计算出 Local Moran’s I 值。结果即为值的参考分布,随后会将该参考分布与实际观测到的 Moran’s I 进行比较,以确定在随机分布中查找到观测值的可能性。默认为 499 次排列;然而,随机样本分布会随着排列的增加而改进,进而提高伪 p 值的精度。如果将 排列数参数设置为 0,则结果为传统 p 值而不是伪 p 值,z 得分基于随机化零假设进行计算。
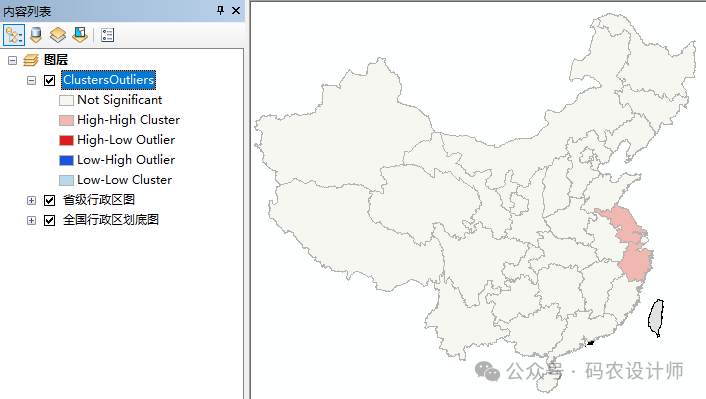
通过输出的结果图层可以看出,浙江省和江苏省出现了High-High Cluster(HH聚集),说明2017年浙江省和江苏省两个省的经济在全国经济中具有一定的带动作用。


本篇文章来源于微信公众号: 码农设计师
{kind=link}