本系列文章配套代码获取有以下三种途径:
-
可以在以下网站查看,该网站是使用JupyterLite搭建的web端Jupyter环境,因此无需在本地安装运行环境即可使用,首次运行浏览器需要下载一些配置文件(大约20M):
https://returu.github.io/Python_Data_Analysis/lab/index.html-
也可以通过百度网盘获取,需要在本地配置代码运行环境,环境配置可以查看【Python基础】2.搭建Python开发环境:
链接:https://pan.baidu.com/s/1MYkeYeVAIRqbxezQECHwcA?pwd=mnsj提取码:mnsj
-
前往GitHub详情页面,单击 code 按钮,选择Download ZIP选项:
https://github.com/returu/Python_Data_Analysis根据《Python for Data Analysis 3rd Edition》翻译整理
—————————————————–
1.离散化和分箱:
1# 将年龄按照18~25,26~35,36~60,60~100分组
2>>> ages = [22,21,25,28,21,23,36,33,65,46,40,39]
3>>> bins = [18,25,35,60,100]
-
cut()方法
pandas.cut方法返回的是一个特殊的Categorical对象。
1>>> ages_cate = pd.cut(ages,bins)
2>>> ages_cate
3[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (25, 35], (60, 100], (35, 60], (35, 60], (35, 60]]
4Length: 12
5Categories (4, interval[int64, right]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]
输出结果描述了 pandas.cut 计算的 bin。每个 bin 由一个特殊的(pandas 独有的)区间值类型标识,其中包含每个 bin 的下限和上限。
1# 类别数组
2>>> ages_cate.categories
3IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]], dtype='interval[int64, right]')
4
5# 不同年龄在类别数组中的索引值
6>>> ages_cate.codes
7array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 2], dtype=int8)
1# 类别数组
2>>> ages_cate.categories
3IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]], dtype='interval[int64, right]')
4
5# 不同年龄在类别数组中的标签
6>>> ages_cate.codes
7array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 2], dtype=int8)
8
9# pandas.cut 结果中的 箱(bin)数量的 计数
10>>> pd.value_counts(ages_cate)
11(18, 25] 5
12(35, 60] 4
13(25, 35] 2
14(60, 100] 1
15dtype: int64
默认情况下,区间的左边为开放的(不包括)、右边为封闭的(包括),可以通过传递 right=False 参数改变区间形式。
1>>> ages_cate = pd.cut(ages,bins)
2>>> ages_cate.categories
3IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]], dtype='interval[int64, right]')
4
5>>> ages_cate2 = pd.cut(ages,bins,right=False)
6>>> ages_cate2.categories
7IntervalIndex([[18, 25), [25, 35), [35, 60), [60, 100)], dtype='interval[int64, left]')还可以通过向 labels 参数传递一个列表或数组来自定义箱名。
1>>> ages = [22,21,25,28,21,23,36,33,65,46,40,39]
2>>> bins = [18,25,35,60,100]
3>>> group_names =['未成年','成年','中年','老年']
4
5>>> ages_cate = pd.cut(ages,bins,labels=group_names)
6>>> ages_cate
7['未成年', '未成年', '未成年', '成年', '未成年', ..., '成年', '老年', '中年', '中年', '中年']
8Length: 12
9Categories (4, object): ['未成年' < '成年' < '中年' < '老年']
也可以传入希望切分的箱的数量,系统会根据最大值和最小值自动计算出等长的箱,其中precision选项用于设置精度限制。
1>>> ages = [22,21,25,28,21,23,36,33,65,46,40,39]
2>>> ages_cate = pd.cut(ages,4,precision=2)
3>>> ages_cate
4[(20.96, 32.0], (20.96, 32.0], (20.96, 32.0], (20.96, 32.0], (20.96, 32.0], ..., (32.0, 43.0], (54.0, 65.0], (43.0, 54.0], (32.0, 43.0], (32.0, 43.0]]
5Length: 12
6Categories (4, interval[float64, right]): [(20.96, 32.0] < (32.0, 43.0] < (43.0, 54.0] < (54.0, 65.0]]
-
qcut()方法
pandas.qcut 方法是一个与分箱操作密切相关的函数,是基于样本分位数进行分箱操作。取决于数据分布,pandas.cut 通常不会使得每个箱中具有相同数量的样本点。由于pandas.qcut 使用样本分位数,可以获得等长的箱。 1>>> data = np.random.randn(100)
2>>> data_cate = pd.qcut(data,4) # 切分成四份
3>>> data_cate
4[(-2.092, -0.698], (-2.092, -0.698], (-0.242, 0.341], (-0.698, -0.242], (-0.242, 0.341], ..., (-2.092, -0.698], (-0.698, -0.242], (0.341, 2.385], (-0.698, -0.242], (-0.242, 0.341]]
5Length: 100
6Categories (4, interval[float64, right]): [(-2.092, -0.698] < (-0.698, -0.242] < (-0.242, 0.341] < (0.341, 2.385]]
7
8>>> pd.value_counts(data_cate)
9(-2.092, -0.698] 25
10(-0.698, -0.242] 25
11(-0.242, 0.341] 25
12(0.341, 2.385] 25
13dtype: int64
1>>> data_cate = pd.qcut(data,[0,0.1,0.5,0.9,1])
2>>> data_cate
3[(-2.092, -1.17], (-2.092, -1.17], (-0.242, 1.038], (-1.17, -0.242], (-0.242, 1.038], ..., (-2.092, -1.17], (-1.17, -0.242], (1.038, 2.385], (-1.17, -0.242], (-0.242, 1.038]]
4Length: 100
5Categories (4, interval[float64, right]): [(-2.092, -1.17] < (-1.17, -0.242] < (-0.242, 1.038] < (1.038, 2.385]]
6
7>>> pd.value_counts(data_cate)
8(-1.17, -0.242] 40
9(-0.242, 1.038] 40
10(-2.092, -1.17] 10
11(1.038, 2.385] 10
12dtype: int64
2.检测和过滤异常值
过滤或转换异常值主要是应用数组操作的问题。
例如,需要将DataFrame中的数值限制在 -50 到50 之间,大于50的设置为50,小于-50的设置为-50。
1>>> data = pd.DataFrame(np.random.randint(-100,100,(6, 4)))
2>>> data
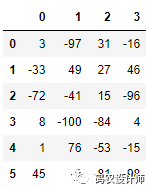
假设你想在其中一列中查找绝对值超过 50 的值。
1>>> col = data[2]
2>>> col[col.abs() > 50]
33 -84
44 -53
55 -81
6Name: 2, dtype: int32
如要选择值超过 50 或 –50 的所有行,可以在布尔值DataFrame上使用 any 方法。
1>>> data[(data.abs() > 50).any(axis="columns")]
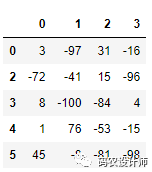
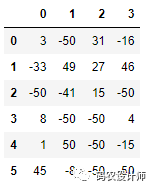
通过np.sign(),限制值超出 –50 到 50的区间。
其中, np.sign() 方法之前介绍过,是根据数据中值的正负分别生成1和-1的数值。
1>>> data[(data.abs() > 50)] = np.sign(data)*50
2>>> data
本篇文章来源于微信公众号: 码农设计师
{kind=link}