本系列文章配套代码获取有以下三种途径:
-
可以在以下网站查看,该网站是使用JupyterLite搭建的web端Jupyter环境,因此无需在本地安装运行环境即可使用,首次运行浏览器需要下载一些配置文件(大约20M):
https://returu.github.io/Python_Data_Analysis/lab/index.html-
也可以通过百度网盘获取,需要在本地配置代码运行环境,环境配置可以查看【Python基础】2.搭建Python开发环境:
链接:https://pan.baidu.com/s/1MYkeYeVAIRqbxezQECHwcA?pwd=mnsj提取码:mnsj
-
前往GitHub详情页面,单击 code 按钮,选择Download ZIP选项:
https://github.com/returu/Python_Data_Analysis根据《Python for Data Analysis 3rd Edition》翻译整理
—————————————————–
使用 numpy.random.permutation 函数可以排列(随机重新排序)一个Series 或 DataFrame 中的行。
在调用 permutation 的时候,根据你想要的轴长度生成一个表示新排序的整数数组。
1>>> data = pd.DataFrame(np.arange(24).reshape(6,4))
2>>> data
3 0 1 2 3
40 0 1 2 3
51 4 5 6 7
62 8 9 10 11
73 12 13 14 15
84 16 17 18 19
95 20 21 22 23
10
11>>> sampler = np.random.permutation(6)
12>>> sampler
13array([4, 2, 3, 5, 0, 1])
然后可以在基于iloc 索引或等价的 take 函数中使用该数组。
1>>> data.iloc[sampler]
2 0 1 2 3
34 16 17 18 19
42 8 9 10 11
53 12 13 14 15
65 20 21 22 23
70 0 1 2 3
81 4 5 6 7
9
10>>> data.take(sampler)
11 0 1 2 3
124 16 17 18 19
132 8 9 10 11
143 12 13 14 15
155 20 21 22 23
160 0 1 2 3
171 4 5 6 7
通过使用 axis="columns" 调用 take 函数可以选择列的排列:
1>>> sampler = np.random.permutation(4)
2>>> sampler
3array([3, 0, 2, 1])
4
5>>> data.take(sampler,axis="columns")
6 3 0 2 1
70 3 0 2 1
81 7 4 6 5
92 11 8 10 9
103 15 12 14 13
114 19 16 18 17
125 23 20 22 21
要选择不放回的随机子集(同一行不能出现两次),可以在 Series 和 DataFrame 上使用 sample 方法。
1>>> data.sample(3)
2 0 1 2 3
30 0 1 2 3
43 12 13 14 15
51 4 5 6 7
要生成带有替代值的样本(允许有重复选择),需要将 replace=True 传入 sample 方法。
1>>> data.sample(6,replace=True)
2 0 1 2 3
32 8 9 10 11
41 4 5 6 7
54 16 17 18 19
64 16 17 18 19
70 0 1 2 3
85 20 21 22 23
2.计算指标/虚拟变量
统计建模或机器学习应用中的一种类型的转换是将分类变量转换为虚拟或指标矩阵。
2.1 DataFrame 中一行只属于一个类别:
如果 DataFrame 中的一列有 k 个不同的值,将生成一个k列的值为1或0的矩阵或DataFrame 。
Pandas 有一个 pandas.get_dummies 函数来执行此操作。
让我们考虑一个DataFrame示例 :
1>>> df = pd.DataFrame({"key": ["b", "b", "a", "c", "a", "b"],"value": [11,22,33,44,55,66]})
2>>> df
3 key value
40 b 11
51 b 22
62 a 33
73 c 44
84 a 55
95 b 66
10
11>>> pd.get_dummies(df["key"])
12 a b c
130 0 1 0
141 0 1 0
152 1 0 0
163 0 0 1
174 1 0 0
185 0 1 0
在某些情况下,你可能希望在指标 DataFrame 中的列上添加前缀, pandas.get_dummies 有一个用于执行此操作的前缀参数prefix。
1>>> dummies = pd.get_dummies(df["key"],prefix="KEY")
2>>> dummies
3 KEY_a KEY_b KEY_c
40 0 1 0
51 0 1 0
62 1 0 0
73 0 0 1
84 1 0 0
95 0 1 0然后通过 DataFrame.join 方法将其与其他数据合并。
1>>> df_with_dummy = df[["value"]].join(dummies)
2>>> df_with_dummy
3 value KEY_a KEY_b KEY_c
40 11 0 1 0
51 22 0 1 0
62 33 1 0 0
73 44 0 0 1
84 55 1 0 0
95 66 0 1 0
2.2 DataFrame 中的一行属于多个类别
如果 DataFrame 中的一行属于多个类别,我们必须使用不同的方法来创建虚拟变量。
1>>> df = pd.DataFrame({"key": ["b|c", "a|b|c", "a", "a|c", "b|d", "c|e"],"value": [11,22,33,44,55,66]})
2>>> df
3 key value
40 b|c 11
51 a|b|c 22
62 a 33
73 a|c 44
84 b|d 55
95 c|e 66Pandas 实现了一个特殊的 Series 方法 str.get_dummies(以 str. 开头的方法将在后面的字符串操作中进行更详细的讨论)来处理这种通过分隔字符串编码的情况。
1>>> dummies = df["key"].str.get_dummies("|")
2>>> dummies
3 a b c d e
40 0 1 1 0 0
51 1 1 1 0 0
62 1 0 0 0 0
73 1 0 1 0 0
84 0 1 0 1 0
95 0 0 1 0 1
然后,可以通过 DataFrame.join 方法将其与其他数据合并,并使用add_prefix 方法将前缀添加到虚拟变量 DataFrame 中的列名中。
1>>> df_with_dummy = df.join(dummies.add_prefix("KEY_"))
2>>> df_with_dummy
3 key value KEY_a KEY_b KEY_c KEY_d KEY_e
40 b|c 11 0 1 1 0 0
51 a|b|c 22 1 1 1 0 0
62 a 33 1 0 0 0 0
73 a|c 44 1 0 1 0 0
84 b|d 55 0 1 0 1 0
95 c|e 66 0 0 1 0 1
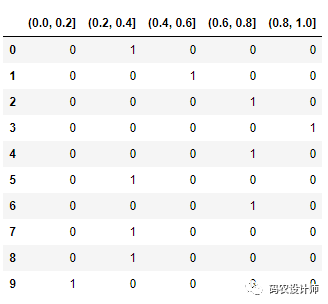
2.3 pandas.get_dummies + pandas.cut
统计应用程序的一个有用方法是将 pandas.get_dummies 与像 pandas.cut这样的离散化函数结合起来。
1>>> value = np.random.uniform(size=10)
2>>> value
3array([0.25484881, 0.42672166, 0.75541075, 0.80483537, 0.73278982,
4 0.35195332, 0.68100908, 0.26854481, 0.30220373, 0.06221511])
5
6>>> bins = [0 ,0.2 ,0.4 , 0.6 ,0.8 ,1]
7
8>>> pd.cut(value , bins)
9[(0.2, 0.4], (0.4, 0.6], (0.6, 0.8], (0.8, 1.0], (0.6, 0.8], (0.2, 0.4], (0.6, 0.8], (0.2, 0.4], (0.2, 0.4], (0.0, 0.2]]
10Categories (5, interval[float64, right]): [(0.0, 0.2] < (0.2, 0.4] < (0.4, 0.6] < (0.6, 0.8] < (0.8, 1.0]]
11
12>>> pd.get_dummies(pd.cut(value , bins))
本篇文章来源于微信公众号: 码农设计师
{kind=link}