本系列文章配套代码获取有以下三种途径:
-
可以在以下网站查看,该网站是使用JupyterLite搭建的web端Jupyter环境,因此无需在本地安装运行环境即可使用,首次运行浏览器需要下载一些配置文件(大约20M):
https://returu.github.io/Python_Data_Analysis/lab/index.html-
也可以通过百度网盘获取,需要在本地配置代码运行环境,环境配置可以查看【Python基础】2.搭建Python开发环境:
链接:https://pan.baidu.com/s/1MYkeYeVAIRqbxezQECHwcA?pwd=mnsj提取码:mnsj
-
前往GitHub详情页面,单击 code 按钮,选择Download ZIP选项:
https://github.com/returu/Python_Data_Analysis根据《Python for Data Analysis 3rd Edition》翻译整理
—————————————————–
1.分类计算:
与非编码版本(如字符串数组)相比,在 Pandas 中使用 Categorical 与其操作一样。Pandas 的某些部分,如 groupby 函数,在处理分类时会表现更好。还有一些函数可以利用ordered 标志。
下面实例中,首先生成一些随机数字数据并使用 pandas.qcut 分箱函数。这将返回pandas.Categorical;我们在前面使用了 pandas.qcut ,但忽略了分类如何工作的细节。
1>>> rng = np.random.default_rng(seed=12345)
2
3>>> draws = rng.standard_normal(1000)
4
5>>> bins = pd.qcut(draws, 4)
6>>> bins
7[(-3.121, -0.675], (0.687, 3.211], (-3.121, -0.675], (-0.675, 0.0134], (-0.675, 0.0134], ..., (0.0134, 0.687], (0.0134, 0.687], (-0.675, 0.0134], (0.0134, 0.687], (-0.675, 0.0134]]
8Length: 1000
9Categories (4, interval[float64, right]): [(-3.121, -0.675] < (-0.675, 0.0134] < (0.0134, 0.687] < (0.687, 3.211]]
通过 labels 参数对分组命名。
1>>> bins = pd.qcut(draws, 4, labels=['Q1', 'Q2', 'Q3', 'Q4'])
2>>> bins
3['Q1', 'Q4', 'Q1', 'Q2', 'Q2', ..., 'Q3', 'Q3', 'Q2', 'Q3', 'Q2']
4Length: 1000
5Categories (4, object): ['Q1' < 'Q2' < 'Q3' < 'Q4']
6
7>>> bins.codes[:10]
8array([0, 3, 0, 1, 1, 0, 0, 2, 2, 0], dtype=int8)
9
10>>> bins.categories
11Index(['Q1', 'Q2', 'Q3', 'Q4'], dtype='object')
带标签的 bins 分类数据并不包含有关数据中 箱体边界的信息,因此我们可以使用 groupby来提取一些汇总统计信息。
1>>> bins = pd.Series(bins, name='quartile')
2
3>>> result = pd.Series(draws).groupby(bins).agg(['count', 'min', 'max']).reset_index()
4>>> result
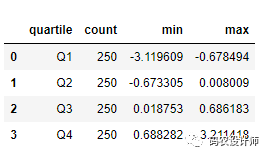
结果中的‘quartile’列保留了原始分类信息,包括来自箱子的排序。
1>>> result['quartile']
20 Q1
31 Q2
42 Q3
53 Q4
6Name: quartile, dtype: category
7Categories (4, object): ['Q1' < 'Q2' < 'Q3' < 'Q4']
2.分类方法:
包含分类数据的Series 有几个类似于 Series.str 的专用字符串方法,也提供了对类别(categories )和代码(codes)的快捷访问方式。
1>>> s = pd.Series(['a', 'b', 'c', 'd'] * 2)
2>>> s
30 a
41 b
52 c
63 d
74 a
85 b
96 c
107 d
11dtype: object
12
13>>> cat_s = s.astype('category')
14>>> cat_s
150 a
161 b
172 c
183 d
194 a
205 b
216 c
227 d
23dtype: category
24Categories (4, object): ['a', 'b', 'c', 'd']
特殊属性 cat提供了对分类方法的访问。
1>>> cat_s.cat.codes
20 0
31 1
42 2
53 3
64 0
75 1
86 2
97 3
10dtype: int8
假设我们知道该数据的实际类别集合超出了数据中观察到的四个值。我们可以使用 set_categories方法来改变它们。
1>>> actual_categories = ['a', 'b', 'c', 'd', 'e']
2>>> cat_s2 = cat_s.cat.set_categories(actual_categories)
3>>> cat_s2
40 a
51 b
62 c
73 d
84 a
95 b
106 c
117 d
12dtype: category
13Categories (5, object): ['a', 'b', 'c', 'd', 'e']
虽然看起来数据没有变化,但新类别将反映在使用它们的操作中。例如,value_counts 结果。
1>>> cat_s.value_counts()
2a 2
3b 2
4c 2
5d 2
6dtype: int64
7
8>>> cat_s2.value_counts()
9a 2
10b 2
11c 2
12d 2
13e 0
14dtype: int64
在大型数据集中,分类通常用作节省内存和提高性能的便捷工具。在过滤大型 DataFrame 或 Series 后,许多类别可能不会出现在数据中。为了解决这个问题,我们可以使用 remove_unused_categories 方法来去除未观察到的类别。
1>>> cat_s3 = cat_s[cat_s.isin(['a', 'b'])]
2>>> cat_s3
30 a
41 b
54 a
65 b
7dtype: category
8Categories (4, object): ['a', 'b', 'c', 'd']
9
10>>> cat_s3.cat.remove_unused_categories()
110 a
121 b
134 a
145 b
15dtype: category
16Categories (2, object): ['a', 'b']
Pandas中Series 中的分类方法:
| 方法 | 说明 |
| add_categories | 在现有类别的末尾添加新的(未使用的)类别 |
| as_ordered | 对类别排序 |
| as_unordered | 使类别无序 |
| remove_categories | 删除类别,将被删除的值设置为null |
| remove_unused_categories | 删除未出现在数据中的所有类别值 |
| rename_categories |
用一组新类别名称替换现有类别;不会更改类别的数量 |
| reorder_categories | 行为类似于 rename_categories,但结果是经过排序的类别 |
| set_categories | 用一组新类别替换现有类别;可以添加或删除类别 |
本篇文章来源于微信公众号: 码农设计师
{kind=link}