Python受欢迎的原因之一就是其计算生态丰富,据不完全统计,Python 目前为止有约13万+的第三方库。
本系列将会陆续整理分享一些有趣、有用的第三方库。
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1FSGLd7aI_UQlCQuovVHc_Q?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/Python_Ecosystempip install jiebapython==3.7.3jieba==0.42.1protobuf==3.20.0
-
jieba.cut():
jieba.cut(sentence,cut_all,HMM,use_paddle)-
sentence:需要分词的字符串; -
cut_all:用来控制是否采用全模式; -
HMM:用来控制是否使用 HMM 模型; -
use_paddle:参数用来控制是否使用paddle模式下的分词模式。
seg_list = jieba.cut("小明来到北京清华大学", cut_all=False)
print("精确模式: " + "/ ".join(seg_list))
# 精确模式: 小明/ 来到/ 北京/ 清华大学
seg_list = jieba.cut("小明来到北京清华大学", cut_all=True)
print("全模式: " + "/ ".join(seg_list))
# 全模式: 小/ 明来/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学
jieba.enable_paddle()# 启动paddle模式
seg_list = jieba.cut("小明来到北京清华大学",use_paddle=True)
print("Paddle Mode: " + '/'.join(seg_list))
# Paddle Mode: 小明/来到/北京清华大学
-
jieba.cut_for_search():
jieba.cut_for_search(sentence,HMM)-
sentence:需要分词的字符串; -
HMM:是否使用 HMM 模型。
隐马尔可夫模型(HMM)在新词发现中的应用主要体现在中文分词领域,尤其是在处理未登录词(即不在词典中的词)时。通过分析上下文关系,HMM能够预测未知词汇的可能性分布,从而帮助系统更好地理解和处理新兴网络语言或专业术语。
该方法返回的是一个生成器(generator),因此可以直接遍历,或者使用 list() 函数将其转换为列表。
# 使用 HMM 模型
words = jieba.cut_for_search("小明来到北京清华大学")
list(words)
# ['小明', '来到', '北京', '清华', '华大', '大学', '清华大学']
# 不使用 HMM 模型
words = jieba.cut_for_search("小明来到北京清华大学" , HMM=False)
list(words)
# ['小', '明', '来到', '北京', '清华', '华大', '大学', '清华大学']
-
jieba.load_userdict()载入词典:
虽然 jieba 有新词识别能力,但是有时可能不能满足需求。此时就可以加载一个自定义词典文件,添加 jieba 词库里没有的词,以保证更高的正确率。
自定义词典格式如下所示:一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
新词一 3 i新词二 5新词三 nz新词四
jieba.load_userdict(file_name) 机器学习 5 n深度学习 3 n自然语言处理 10 n
# 需要进行分词的文本
text = "机器学习和深度学习是自然语言处理领域的重要技术。"
seg_list = jieba.cut(text, cut_all=False)
print("分词结果: " + "/ ".join(seg_list))
# 分词结果: 机器/ 学习/ 和/ 深度/ 学习/ 是/ 自然语言/ 处理/ 领域/ 的/ 重要/ 技术/ 。
# 加载自定义词典文件
jieba.load_userdict('mydict.txt')
seg_list = jieba.cut(text, cut_all=False)
print("加载自定义词典后的分词结果: " + "/ ".join(seg_list))
# 加载自定义词典后的分词结果: 机器学习/ 和/ 深度学习/ 是/ 自然语言处理/ 领域/ 的/ 重要/ 技术/ 。
-
jieba.add_word() 和 jieba.del_word() 修改词典:
使用 add_word(word, freq=None, tag=None) 和 del_word(word) 可在程序中动态修改词典。
# 需要进行分词的文本
text = "机器学习和深度学习是自然语言处理领域的重要技术。"
seg_list = jieba.cut(text, cut_all=False)
print("分词结果: " + "/ ".join(seg_list))
# 分词结果: 机器学习/ 和/ 深度学习/ 是/ 自然语言处理/ 领域/ 的/ 重要/ 技术/ 。
# 加载自定义词典文件
jieba.add_word('自然语言处理领域')
seg_list = jieba.cut(text, cut_all=False)
print("添加自定义词后的分词结果: " + "/ ".join(seg_list))
# 添加自定义词后的分词结果: 机器学习/ 和/ 深度学习/ 是/ 自然语言处理领域/ 的/ 重要/ 技术/ 。
# 加载自定义词典文件
jieba.del_word('机器学习')
seg_list = jieba.cut(text, cut_all=False)
print("删除自定义词后的分词结果: " + "/ ".join(seg_list))
# 删除自定义词后的分词结果: 机器/ 学习/ 和/ 深度学习/ 是/ 自然语言处理领域/ 的/ 重要/ 技术/ 。
-
jieba.suggest_freq() 调节词频:
使用 suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
该函数是 jieba 库提供的一个用于调整词语频率的函数,它可以用来影响分词结果,特别是在处理特定的词语或者专有名词时非常有用。
jieba.suggest_freq(segment, tune=True)其中:
-
segment:待调整词频的词语,可以是一个词语(字符串),也可以是包含多个词语的列表或元组;
-
tune:布尔类型的变量,表示是否开启调优模式,默认为 True。当该参数为 True 时,该函数会根据语料库中词语的出现频率来调整词频。这通常用于对特定的词语进行手动调整,以解决分词不准确的问题,比如某个专有名词或新词在默认分词中被错误切分。
例如,在下面的示例中,原本的分词结果将“机器学习”分成了“机器/学习”两部分。通过使用 jieba.suggest_freq 函数来调整“机器学习”的词频,可以得到更准确的分词结果:
# 需要进行分词的文本
text = "小明在机器学习方面有很高的研究成果。"
# 分词前的结果
seg_list = jieba.cut(text, cut_all=False)
print("分词结果: " + "/ ".join(seg_list))
# 分词结果: 小明/ 在/ 机器/ 学习/ 方面/ 有/ 很/ 高/ 的/ 研究成果/ 。
# 调整单词"机器学习"的词频
jieba.suggest_freq("机器学习", tune=True)
# 分词后的结果
seg_list = jieba.cut(text, cut_all=False)
print("调节词频后的分词结果: " + "/ ".join(seg_list))
# 调节词频后的分词结果: 小明/ 在/ 机器学习/ 方面/ 有/ 很/ 高/ 的/ 研究成果/ 。
-
基于 TF-ID 算法:
jieba.analyse.extract_tags(sentence,topK=20,withWeight=False,allowPOS=())
其中:
-
sentence:待提取的文本;
-
topK:返回几个 TF/IDF 权重最大的关键词,默认值为 20; -
withWeight:是否一并返回关键词权重值,默认值为 False,此时将返回一个包含关键词的列表。如果为 True,将返回一个包含 (关键词, 权重) 元组的列表; -
allowPO:仅包括指定词性的词,默认值为空,即不筛选。
示例代码:
import jieba.analyse
# 待提取的文本
text = "我爱自然语言处理,尤其是中文分词"
# 使用 TF-IDF 算法提取关键词
keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True)
# 打印关键词及其权重
print("TF-IDF 算法提取的关键词:")
for tag, weight in keywords:
print(f"tag: {tag} weight:{weight}")
返回结果如下:
TF-IDF 算法提取的关键词:
tag: 分词 weight: 2.340691
tag: 自然语言 weight: 2.086988
tag: 中文 weight: 1.629621
tag: 处理 weight: 1.082171
tag: 尤其 weight: 1.055573
另外,关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径,使用 jieba.analyse.set_idf_path(file_name) 函数进行设置 。
-
基于 TextRank 算法:
TextRank 算法的基本思想是将文本中的词语表示为一张无向有权图,其中词为图的节点,词之间的共现关系体现为图的边的权值。通过计算图中节点的权重,找出权重排名 TopK 的节点,即关键词。
基于 TextRank 算法的关键词提取功能的函数:
jieba.analyse.textrank(sentence,topK=20,withWeight=False,allowPOS=('ns', 'n', 'vn', 'v'))
其中,各参数与jieba.analyse.extract_tags()函数一样,不过需要注意的是,jieba.analyse.textrank()函数默认过滤词性。
示例代码:
import jieba.analyse
# 待提取的文本
text = "我爱自然语言处理,尤其是中文分词。自然语言处理是人工智能领域的一个重要方向,它涉及到计算机科学与语言学的交叉。"
# 使用 TextRank 算法提取关键词
keywords = jieba.analyse.textrank(text, topK=5, withWeight=True , allowPOS=('ns', 'n', 'vn', 'v'))
# 打印关键词及其权重
print("TextRank 算法提取的关键词:")
for tag, weight in keywords:
print(f"{tag} {weight}")
返回结果如下:
TextRank 算法提取的关键词:
处理 1.0
领域 0.9437607498603509
涉及 0.8535948576747164
语言学 0.8499729087700155
计算机科学 0.8473805633753241
需要注意的是,因为该函数默认过滤词性,因此可能会由于以下原因导致返回结果为空:
-
文本太短:如果输入的文本太短,可能不足以提取出关键词。
-
参数设置问题:topK 参数设置得太小,或者 allowPOS 参数设置得太严格,导致没有关键词被提取。
-
默认词性标注分词器:
jieba库的默认词性标注分词器是jieba.posseg.dt。这个分词器可以在分词的同时获取每个词的词性标注信息,采用的是和ictclas兼容的标记法。
示例代码:
# 待提取的文本
text = "我爱自然语言处理"
# 使用默认词性标注分词器进行分词和词性标注
words = jieba.posseg.cut(text)
# 打印每个词及其词性
for word, flag in words:
print(f"分词文本: {word} ----> 词性标签:{flag}")
返回结果如下:
分词文本: 我 ----> 词性标签:r
分词文本: 爱 ----> 词性标签:v
分词文本: 自然语言 ----> 词性标签:l
分词文本: 处理 ----> 词性标签:v
-
paddle模式下的词性标注:
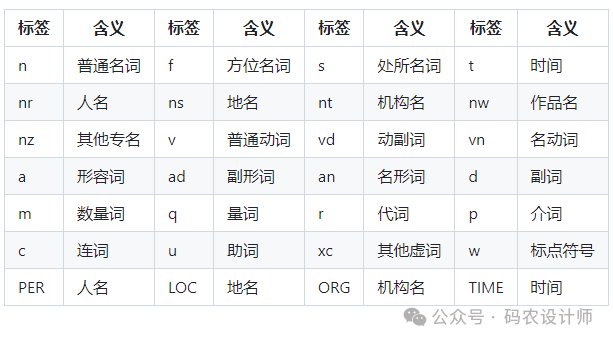
示例代码:
jieba.enable_paddle() #启动paddle模式
# 使用paddle模式下的词性标注
words = jieba.posseg.cut(text,use_paddle=True)
# 打印每个词及其词性
for word, flag in words:
print(f"分词文本: {word} ----> 词性标签:{flag}")
返回结果如下:
分词文本: 我 ----> 词性标签:r
分词文本: 爱 ----> 词性标签:v
分词文本: 自然语言处理 ----> 词性标签:nz
更多内容,可以前往官方GitHub页面查看:
https://github.com/fxsjy/jieba

本篇文章来源于微信公众号: 码农设计师
{kind=link}