本系列配套练习数据下载链接:
链接:https://pan.baidu.com/s/1imKDcw9wZWk_ItR8fwugZw?pwd=mnsj提取码:mnsj
-
数据准备: 提供用于清理、转换和标准化多变量数据的工具,例如波段集统计、创建特征文件工具。 -
降维: 通过主成分分析等方法降低数据维度,简化分析过程,例如主成分分析工具。 -
分类: 支持监督分类和非监督分类,帮助您识别数据中的类别或模式,例如最大似然法分类、Iso 聚类非监督分类、类别概率等工具。 -
聚类: 将具有相似特征的数据聚类在一起,发现数据中的潜在分组,例如 Iso 聚类工具。 -
探索性分析: 提供用于分析多变量数据之间关系的工具,例如树状图工具。
-
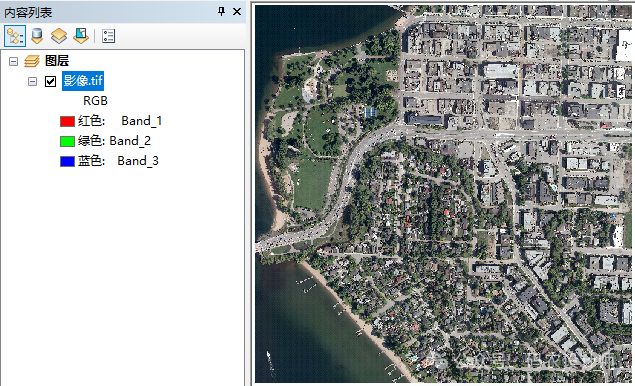
1、概念:
-
初始化聚类中心:算法开始时,会为每个聚类指定一个初始的平均值。这些平均值可能是随机选择的,或者基于某种启发式方法确定。 -
分配样本到聚类:在每次迭代中,算法会计算每个样本(在遥感影像中通常是像元)与当前所有聚类中心之间的欧氏距离。然后,每个样本被分配给距离最近的聚类中心。欧氏距离是衡量多维空间中两点之间“直线”距离的标准方法。 -
重新计算聚类中心:一旦所有样本都被分配给聚类,算法就会基于每个聚类中样本的属性值重新计算聚类中心。这通常是通过计算聚类内所有样本的平均值来完成的。 -
迭代优化:上述两个步骤(分配样本和重新计算聚类中心)会反复执行,直到达到预设的最大迭代次数。迭代次数应该足够大,才能确保执行指定次数的迭代后,像元从一个聚类迁移至另一个聚类的次数最少;从而,使所有聚类变为稳定状态。迭代次数应该随着聚类数的增加而增加。 -
评估和调整聚类数:由于最佳的聚类数通常事先未知,因此可能需要进行多次聚类分析,每次使用不同的聚类数。用户可以根据生成的聚类结果的质量(例如通过目视检查或使用验证数据)来调整聚类数,并重新运行算法以获得更好的结果。
-
数据值和初始聚类平均值分布不均匀。在某些像元值范围内,这些聚类的出现频率可能接近于零。因此,某些最初预定义的聚类平均值可能无法吸收足够多的像元成员。 -
在迭代结束时,将消除由数量少于指定最小类大小值的像元组成的聚类。 -
如果聚类稳定后统计值相似,则聚类将与邻近的聚类进行合并。某些聚类可能彼此间非常接近并且具有十分相似的统计数据,这使得将其分开会导致数据被不必要地分割开。
-
2、工具:
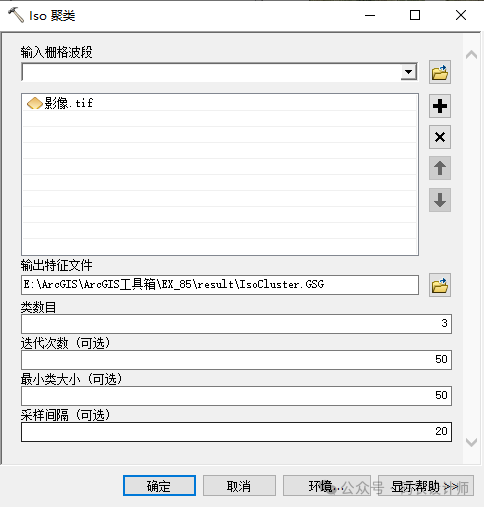
-
类数目:是指聚类过程中可能产生的最大聚类数。类数的最小有效值为二。不存在最大聚类数。通常情况下,聚类越多,所需的迭代就越多; -
迭代次数:是指系统迭代运算的次数,该值应该足够大,以保证像元从一个类迁移到另一类的次数最少,从而使所有的聚类变成稳定状态。迭代次数随着类数目的增加而增大。 -
最小类大小:是指一个有效类多包含的最少像元数。要提供充足的必要统计数据,生成特征文件以供将来分类使用,每个聚类都应当含有足够的像元来准确地表示聚类。最小类大小输入的值应大约比输入栅格波段中的图层数大 10 倍; -
采样间隔:是指相邻零次采样的空间间隔,若间距过大会造成重要信息的损失,若间距过小会增加系统计算量。
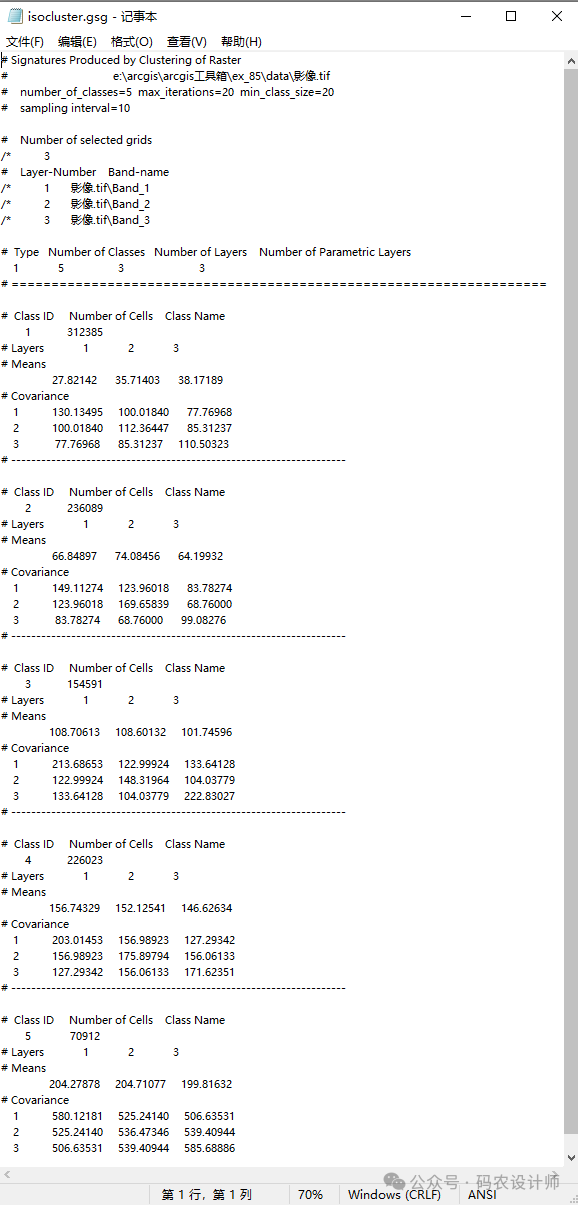
以下为 Iso 聚类创建的特征文件:
-
文件开头是一个添加注释的文件头,显示了执行 iso 聚类所使用的参数值。 -
输出特征文件中的类 ID 值以一开始,然后按顺序增加至输入类的数量。 -
类名称为可选名称,可以在创建文件后使用文本编辑器输入。输入的类名称必须为单个字符串,并且长度不得超过 14 个字母数字字符。
————————————————-
《ArcGIS工具箱》系列内容目录(持续更新):
| …… |
|
| 73.叠加分析——模糊隶属度 |
74.叠加分析——模糊叠加 |
| 75.叠加分析——查找区域 |
76.栅格综合——聚合 |
| 77.栅格综合——扩展 |
78.栅格综合——收缩 |
| 79.栅格综合——蚕食 |
80.栅格综合——细化 |
| 81.栅格综合——边界清理 |
82.栅格综合——众数滤波 |
| 83.栅格综合——区域合并 |
84.多元分析——波段集统计 |
| …… |


本篇文章来源于微信公众号: 码农设计师
{kind=link}