本系列文章配套代码获取有以下三种途径:
-
可以在以下网站查看,该网站是使用JupyterLite搭建的web端Jupyter环境,因此无需在本地安装运行环境即可使用,首次运行浏览器需要下载一些配置文件(大约20M):
https://returu.github.io/Python_Data_Analysis/lab/index.html-
也可以通过百度网盘获取,需要在本地配置代码运行环境,环境配置可以查看【Python基础】2.搭建Python开发环境:
链接:https://pan.baidu.com/s/1MYkeYeVAIRqbxezQECHwcA?pwd=mnsj提取码:mnsj
-
前往GitHub详情页面,单击 code 按钮,选择Download ZIP选项:
https://github.com/returu/Python_Data_Analysis根据《Python for Data Analysis 3rd Edition》翻译整理
—————-————————————-
在处理非常大的文件或找出正确的参数集以正确处理大文件时,可能只需要读取文件的一小部分或以小块遍历文件。
本次以全球幸福报告指数数据“happiness_report.csv”为例。
1.读取部分文件:
使用read_csv读取数据。
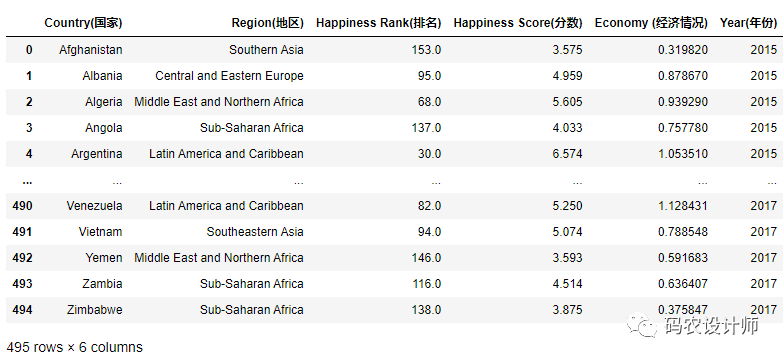
1>>> df = pd.read_csv("./data/happiness_report.csv",encoding="ANSI")
2>>> df
显示结果如下所示,省略号 … 表示 DataFrame 中间的行已被省略。
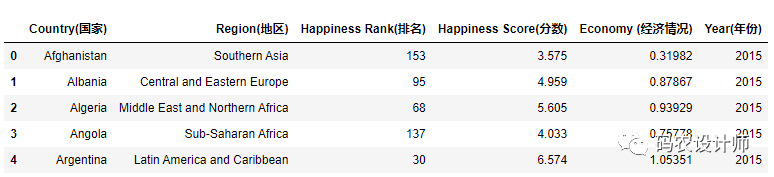
如果只想读取少量行(避免读取整个文件),需要指定 nrows 参数。
1>>> df = pd.read_csv("./data/happiness_report.csv",encoding="ANSI",nrows=5)
2>>> df
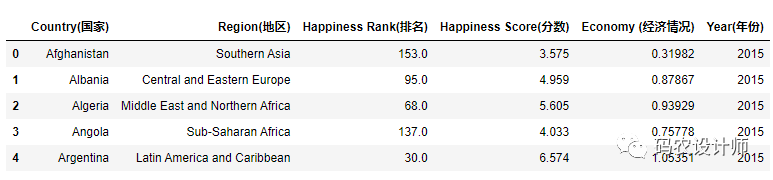
使用 head() 方法,将会只选出文件的前五行。
1>>> df = pd.read_csv("./data/happiness_report.csv",encoding="ANSI")
2>>> df.head()
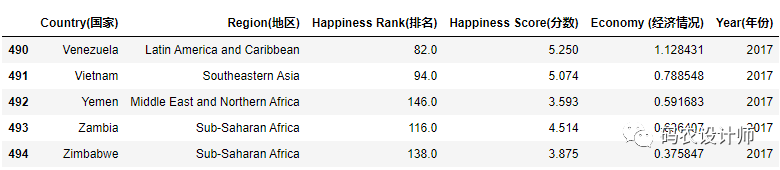
使用 tail() 方法,将会只选出文件的最后五行。
1>>> df = pd.read_csv("./data/happiness_report.csv",encoding="ANSI")
2>>> df.tail()
2.分块读取文件:
如需分块读取文件,需要将 chunksize 参数指定为每一块的行数。
1>>> chunker = pd.read_csv("./data/happiness_report.csv",encoding="ANSI",chunksize=99)
2>>> type(chunker)
3pandas.io.parsers.readers.TextFileReader
返回的 TextFileReader 对象允许你根据块大小迭代文件的各个部分。
可以看到数据被分成了5块读取(495/99=5)。
1>>> n = 1
2>>> for piece in chunker:
3... print(n)
4... n +=1
5
61
72
83
94
105
TextFileReader 还具有一个 get_chunk 方法,能够读取任意大小的数据块。
本篇文章来源于微信公众号: 码农设计师
{kind=link}