本系列文章配套代码获取有以下三种途径:
-
可以在以下网站查看,该网站是使用JupyterLite搭建的web端Jupyter环境,因此无需在本地安装运行环境即可使用,首次运行浏览器需要下载一些配置文件(大约20M):
https://returu.github.io/Python_Data_Analysis/lab/index.html-
也可以通过百度网盘获取,需要在本地配置代码运行环境,环境配置可以查看【Python基础】2.搭建Python开发环境:
链接:https://pan.baidu.com/s/1MYkeYeVAIRqbxezQECHwcA?pwd=mnsj提取码:mnsj
-
前往GitHub详情页面,单击 code 按钮,选择Download ZIP选项:
https://github.com/returu/Python_Data_Analysis根据《Python for Data Analysis 3rd Edition》翻译整理
—————————————————–
1.二进制数据读写:
使用python内建的pickle序列化模块进行二进制格式操作是存储数据做高效、最方便的方式之一。
使用to_pickle方法可以将数据以pickle格式写入硬盘。
读取时,直接使用pandas.read_pickle方法读取。
1>>> df = pd.read_csv("./data/PM25.csv",encoding='gb18030')
2
3# 将数据以pickle格式写入硬盘
4>>> df.to_pickle("./data/example_pickle")
5
6# 读取pickle格式文件
7>>> pd.read_pickle("./data/example_pickle")
需注意的是,因为pickle很难确保格式的长期有效性(今天被pickle化的对象可能回头会因为库的新版本而无法反序列化),因此仅被推荐作为短期的存储格式。
2.excel数据读写:
虽说日常常用的数据格式为csv,不过pandas也支持对excel文件的读写操作。Pandas 支持使用 pandas.ExcelFile 类或 pandas.read_excel 函数读取存储在 Excel 2003(及更高版本)文件中的表格数据。在内部,这些工具使用附加包 xlrd 和 openpyxl 分别读取老版本的 XLS 和新版本的 XLSX 文件。
-
ExcelFile类
1# 使用 pandas.ExcelFile 类来创建一个实例
2>>> xlsx = pd.ExcelFile("./data/PM25.xlsx")
3
4# 该对象可以显示文件中可用工作表名称的列表
5>>> xlsx.sheet_names
6['Sheet1']
7
8# 然后使用 parse 将存储在工作表中的数据读入 DataFrame 中
9>>> xlsx.parse(sheet_names="Sheet1")
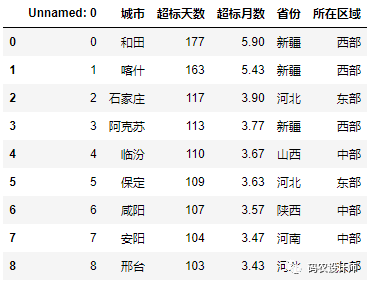
此时 Excel 表有一个索引列,可以通过 index_col参数取消。
1# 此时 Excel 表有一个索引列,可以通过 index_col 参数取消
2>>> xlsx.parse(sheet_name="Sheet1", index_col=0)
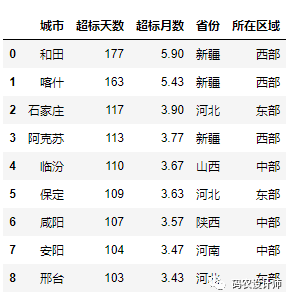
-
read_excel()方法
如果你正在读取一个文件中存在多个工作表,那么使用 pandas.ExcelFile 会更快,但也可以通过更简洁的pandas.read_excel方法读取,如果要读取的excel文件含有多个表,在读取时需要将表名传入。
1>>> xlsx = pd.read_excel("./data/PM25.xlsx",sheet_name="Sheet1", index_col=0)
2>>> xlsx
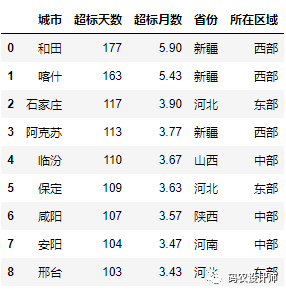
-
ExcelWriter 类
1>>> writer = pd.ExcelWriter("./data/PM25.xlsx")
2>>> df.to_excel(writer,"Sheet1")
3>>> writer.save()-
to_excel()方法
同样,也可以直接使用to_excel方法。
1>>> df.to_excel('./data/PM25.xlsx')
本篇文章来源于微信公众号: 码农设计师
{kind=link}