本系列文章配套代码获取有以下两种途径:
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1XuxKa9_G00NznvSK0cr5qw?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/PyTorchtorch.nn:
Pytorch中的nn模块(torch.nn)是用于构建神经网络的核心组件,它提供了许多预定义的层(模块),使得构建神经网络变得简单、高效且结构化。
另外,nn模块提供了许多预定义的损失函数,用于计算模型预测值与真实值之间的差异,如交叉熵损失(nn.CrossEntropyLoss)、均方误差(nn.MSELoss)等。
使用nn模块实现线性回归:
-
1、生成数据:
PyTorch对神经网络模块的输入进行batch处理(即批处理,指的是一次同时处理的多个数据样本)是一种标准做法,它不仅能够提高计算效率和内存利用率(更高效地利用硬件资源,如GPU的并行计算能力),还能提升模型的稳定性和泛化性能(通过计算整个batch的平均损失来更新模型参数,可以减少梯度更新中的噪声,使梯度下降更加稳定)。
可以使用unsqueeze()方法在输入张量中增加一个新的batch维度。
>>> def get_fake_data(num):
... """
... 生成随机数据,y = 0.5 * x +30并加上一些随机噪声
... """
... x = torch.randint(low = -5, high=30, size=(num,)).to(dtype=torch.float32)
... y = 0.5 * x +30 + torch.randn(num,)
... return x,y
>>> x , y = get_fake_data(num=11)
>>> x = x * 0.1
>>> x.shape , y.shape
(torch.Size([11]), torch.Size([11]))
# 增加batch维度
>>> x = x.unsqueeze(1)
>>> y = y.unsqueeze(1)
>>> x.shape , y.shape
(torch.Size([11, 1]), torch.Size([11, 1]))
-
2、定义函数:
PyTorch提供的所有nn.Module的子类都定义了它们的__call__()方法,这允许我们实例化一个nn.Linear,并像调用函数一样调用它。
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
-
in_features (int):输入特征的数量; -
out_features (int):输出特征的数量; -
bias (bool):线性模型是否包含偏置,默认为True。
本次模型的输入与输出都只有1个特征。
# 定义模型
linear_model = nn.Linear(1,1)
可以通过parameters()方法来访问任何nn.Module或它的子模块拥有的参数列表,该调用会递归到模块的构造函数__init__()定义的子模块中,并返回遇到的所有参数的简单列表。
>>> linear_model.parameters()
<generator object Module.parameters at 0x000001FC623C8580>
>>> list(linear_model.parameters())
[Parameter containing:
tensor([[-0.1188]], requires_grad=True), Parameter containing:
tensor([0.1292], requires_grad=True)]
也可以直接调用weight或bias属性获取参数值。
>>> linear_model.weight
Parameter containing:
tensor([[-0.1188]], requires_grad=True)
>>> linear_model.bias
Parameter containing:
tensor([0.1292], requires_grad=True)
另外,可以直接使用nn模块提供的损失函数,其中包含的均方误差(nn.MSELoss)即使我们之前定义的损失函数loss_fn()。
nn 模块中的损失函数也是nn.Module的子类,因此可以直接创建一个实例并将其作为函数调用。
# 定义损失函数
loss_fn = nn.MSELoss()
最后,再实例化一个优化器。
# 实例化一个优化器
learning_rate=1e-2
optimizer = torch.optim.SGD(linear_model.parameters() , lr=learning_rate)
-
3、循环训练,求解参数值:
最后将循环训练代码进行修改。
需要注意的是,在获取参数值进行绘图部分涉及到两个重要的步骤:
-
首先,使用detach() 方法创建一个新的与当前计算图分离的Tensor,即不会参与到梯度反向传播中;
-
然后,使用numpy() 方法将这个分离的Tensor转换成一个NumPy数组。
from IPython import display
def training_loop(n_epochs , optimizer , model , loss_fn , x , y):
for epoch in range(1 , n_epochs+1):
#前向传播
y_p = model(x)
loss = loss_fn(y_p ,y)
# 梯度归零
optimizer.zero_grad()
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
if epoch % 10 ==0:
display.clear_output(wait=True)
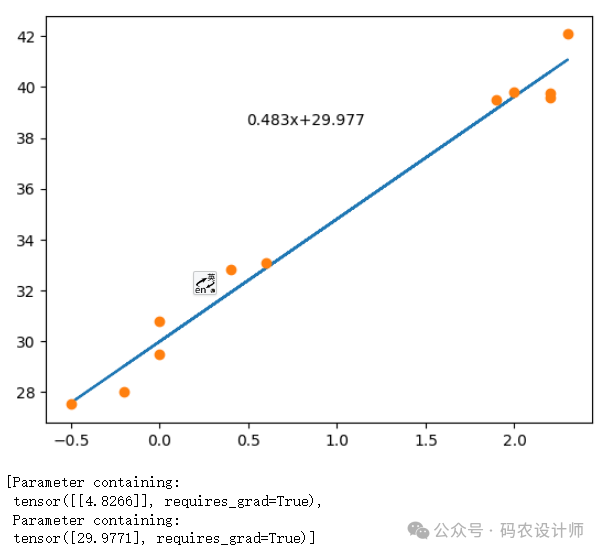
plt.plot(x.detach().numpy() , y_p.detach().numpy())
plt.plot(x.detach().numpy() , y.detach().numpy() , 'o')
# 获取xy轴的范围
xmin,xmax,ymin,ymax = plt.axis()
plt.text(x=xmax*0.2,
y=ymax*0.9,
s=f"{linear_model.weight.detach().numpy().item()*0.1:.3f}x+{linear_model.bias.detach().numpy().item():.3f}")
plt.show()
plt.pause(0.5)
return list(linear_model.parameters())
设置相关参数值并运行,得到参数值。
training_loop(n_epochs=1000 , optimizer=optimizer , model=linear_model , loss_fn=loss_fn , x=x_new , y=y)
更多内容可以前往官网查看:
https://pytorch.org/


本篇文章来源于微信公众号: 码农设计师
{kind=link}