本系列文章配套代码获取有以下两种途径:
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1XuxKa9_G00NznvSK0cr5qw?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/PyTorch卷积神经网络:
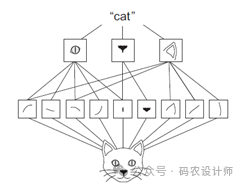
本次我们将使用卷积神经网络来完成同样的分类任务。
CIFAR-10分类:
-
加载CIFAR-10数据集并进行预处理:
# 数据预处理
transform=transforms.Compose([transforms.ToTensor(), # 变换为Tensor
transforms.Normalize((0.4915,0.4823,0.4468),(0.2470,0.2435,0.2616)) # 数据归一化
])
# 下载并加载CIFAR10训练集和测试集
trainset = datasets.CIFAR10('./data/' , train=True , download=True,transform=transform)
train_loader = DataLoader(trainset , batch_size=64 , shuffle=True)
testset = datasets.CIFAR10('./data/' , train=False , download=True,transform=transform)
test_loader = DataLoader(testset , batch_size=64 , shuffle=True)
-
构建网络:
# 构建卷积神经网络模型
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 卷积层
self.bn1 = nn.BatchNorm2d(6) # 标准化层
self.pool = nn.MaxPool2d(2, 2) # 池化层
self.conv2 = nn.Conv2d(6, 16, 5) # 卷积层
self.bn2 = nn.BatchNorm2d(16) # 标准化层
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(nn.functional.relu(self.bn1(self.conv1(x)))) # 在ReLU之前加入BatchNorm
x = self.pool(nn.functional.relu(self.bn2(self.conv2(x)))) # 在ReLU之前加入BatchNorm
x = x.view(-1, 16 * 5 * 5)
x = nn.functional.relu(self.fc1(x)) # relu激活函数
x = nn.functional.relu(self.fc2(x))
x = self.fc3(x)
return x
# 检查是否有可用的GPU,如果有,将网络和数据移动到GPU上
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
net = Net().to(device) # 将网络移到GPU上
net
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(net.parameters(), lr=1e-2, momentum=0.9)
-
训练网络:
# 训练网络
for epoch in range(10): # 多次遍历整个数据集
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
# 获取输入数据
inputs, labels = data[0].to(device), data[1].to(device)
# 清零梯度缓存
optimizer.zero_grad()
# 前向传播,后向传播,优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
running_loss += loss.item()
if i % 200 == 199: # 每200个mini-batches输出一次
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 200))
running_loss = 0.0
print('Finished Training')
[1, 200] loss: 1.832
[1, 400] loss: 1.511
[1, 600] loss: 1.404
[2, 200] loss: 1.268
......
[9, 600] loss: 0.799
[10, 200] loss: 0.738
[10, 400] loss: 0.768
[10, 600] loss: 0.773
Finished Training通过输出结果可以看出,卷积神经网络模型的训练损失低于全连接网络的,说明卷积神经网络通过卷积层能够更有效地从输入数据中提取有用的特征。
-
测试网络:
使用测试集对训练好的模型进行评估,计算模型在未知数据(测试集)上的性能表现,本次选择准确率指标。
# 测试网络
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 10000 test images: {(100 * correct / total)}%' )
输出结果为:
Accuracy of the network on the 10000 test images: 66.07%
可以看到模型在测试集上的预测准确率为66.07%,要高于全连接网络的预测准确率49.46%
-
保存和加载模型:
在PyTorch中保存模型十分简单,首先使用state_dict()来获取模型的所有状态数据,然后使用torch.save()函数将这些数据保存到一个文件中即可。
# 保存模型
torch.save(net.state_dict(), 'model.pth')
后续需要使用模型时,使用load_state_dict()方法来加载保存的状态数据。这样可以确保模型的架构与保存的参数是匹配的。
# 加载模型
net2 = Net() # 首先实例化模型
net2.load_state_dict(torch.load('model.pth')) # 然后加载保存的文件
另外,还可以使用torch.save(model, ‘model.pth’)来保存整个模型(包括架构和参数),并使用model = torch.load(‘model.pth’)来加载。需要注意的是,这种方法严重依赖模型定义方式以及文件路径结构,容易出现问题,因此不推荐使用。
更多内容可以前往官网查看:
https://pytorch.org/


本篇文章来源于微信公众号: 码农设计师
{kind=link}