本系列文章配套代码获取有以下两种途径:
-
通过百度网盘获取:
链接:https://pan.baidu.com/s/1XuxKa9_G00NznvSK0cr5qw?pwd=mnsj提取码:mnsj
-
前往GitHub获取:
https://github.com/returu/PyTorch标准化层:
-
批标准化(Batch Normalization, BN):
-
层标准化(Layer Normalization, LN):
-
实例标准化(Instance Normalization, IN):
-
组标准化(Group Normalization, GN):
BatchNorm2d:
torch.nn.BatchNorm2d(num_features,
eps=1e-05,
momentum=0.1,
affine=True,
track_running_stats=True)
其中:
-
num_features:来自期望输入的特征数,即输入数据的通道数。 -
eps:为了数值稳定性而加到分母里的值。默认值是1e-05。 -
momentum:动态均值和方差的值的一个运行平均值的动量。默认值是0.1。 -
affine:设置为True时,此模块具有可学习的仿射参数(即weight和bias)。默认是True。 -
track_running_stats:设置为True时,此模块将计算并存储运行时的均值和方差,而不是在训练模式下的每个批次中都重新计算它们。这对于在评估(或推理)模式下保持性能非常有用。默认是True。
当affine=True时在PyTorch中,BatchNorm2d层包含两个可学习的参数:weight和bias:
-
weight (γ, gamma):该参数是一个缩放因子,用于调整标准化后的数据分布。在批标准化的过程中,输入数据首先被标准化(即减去均值并除以标准差),然后乘以weight参数。这样做是为了让网络能够学习到原始数据分布的最佳缩放尺度,从而可能提高模型的表达能力。 -
bias (β, beta):该参数是一个偏移量,用于在缩放后的数据上加上一个偏移。与weight类似,bias参数也是可学习的,它允许网络在标准化后的数据上加上一个偏移量,以便更好地适应后续的网络层。
批标准化的公式通常可以表示为:
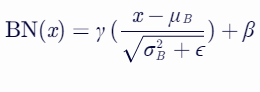
其中:
-
x 是输入数据;
-
μB 和 σB 分别是输入数据在一个小批量内的均值和标准差;
-
γ 是weight参数;
-
β 是bias参数;
-
ϵ 是一个很小的数,用于防止分母为零。
通过训练,网络会学习到合适的γ和β值,以便更有效地优化模型性能。这两个参数的存在使得批量归一化层不仅仅是一个固定的归一化操作,而是一个可以学习和适应的层。
标准化操作:
lena = Image.open('lena.png')
# 将其转换为PyTorch张量
to_tensor = transforms.ToTensor()
lena_tensor = to_tensor(lena).unsqueeze(0)
# 原图的均值和标准差
lena_tensor.mean() , lena_tensor.std()
# 输出结果:(tensor(0.4865), tensor(0.1834))
-
首先创建了一个BatchNorm2d层,并指定期望输入的通道数为1。这意味着该批量归一化层是针对单通道图像设计的。 -
当affine=True时(默认),在BatchNorm2d层中,weight和bias是可学习的参数,它们初始化值分别为1和0。 -
将原图数据传递给BatchNorm2d层进行处理。该层会首先计算输入张量的均值和标准差,然后使用这些统计量对输入进行标准化(即减去均值并除以标准差),最后应用可学习的weight和bias参数进行缩放和偏移,结果存储在out中。由于批量归一化层不会改变输入张量的形状,因此out的形状应该与输入张量的形状相同。 -
由于批量归一化的效果,输出张量的均值应该非常接近0(在这个例子中是-1.3428e-07,几乎为0),而标准差应该非常接近1(在这个例子中是0.9999)。这表明批量归一化成功地将输入数据标准化到了一个具有零均值和单位方差的分布上。
# 创建了一个BatchNorm2d层,期望输入的通道数为1
bn = nn.BatchNorm2d(1)
# weight和bias参数的初始化值
bn.weight.data , bn.bias.data
# 输出结果:(tensor([1.]), tensor([0.]))
# 对图像张量进行标准化操作
out = bn(lena_tensor)
# 结果形状
out.shape
# 输出特征图的均值和标准差
out.mean() , out.std()
# 输出结果:(tensor(-1.3428e-07, grad_fn=<MeanBackward0>),
tensor(0.9999, grad_fn=<StdBackward0>))
更多内容可以前往官网查看:
https://pytorch.org/


本篇文章来源于微信公众号: 码农设计师
{kind=link}